GPU 环境搭建
- 对于裸机环境,只需要安装对应的 GPU Driver 以及 CUDA Toolkit 。
- 对应 Docker 环境,需要额外安装 nvidia-container-toolkit 并配置 docker 使用 nvidia runtime。
- 对应 k8s 环境,需要额外安装对应的 device-plugin 使得 kubelet 能够感知到节点上的 GPU 设备,以便 k8s 能够进行 GPU 管理。
在裸机环境中使用 GPU
裸机中要使用上 GPU 需要安装以下组件:
- GPU Driver
- CUDA Toolkit
二者的关系如 NVIDIA 官网上的这个图所示:
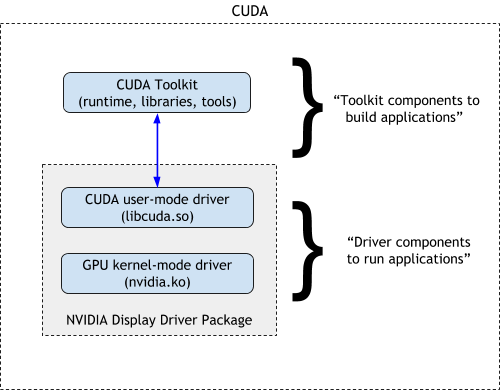
GPU Driver 包括了 GPU 驱动和 CUDA 驱动,CUDA Toolkit 则包含了 CUDA Runtime。
GPU 作为一个 PCIE 设备,只要安装好之后,在系统中就可以通过 lspci 命令查看到,先确认机器上是否有 GPU:
root@gpu-demo:~# lspci | grep NVIDIA
00:07.0 3D controller: NVIDIA Corporation TU104GL [Tesla T4] (rev a1)可以看到,该设备有 1 张 Tesla T4 GPU。
安装驱动
首先到 NVIDIA 驱动页面 下载对应的显卡驱动:
最终下载得到的是一个.run 文件,例如 NVIDIA-Linux-x86_64-565.57.01.run。然后直接 sh 方式运行该文件即可。
sudo sh NVIDIA-Linux-x86_64-565.57.01.run接下来会进入图形化界面,一路选择 yes / ok 就好。
运行以下命令检查是否安装成功。
root@gpu-demo:~# nvidia-smi
Sun Nov 10 11:30:16 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 565.57.01 Driver Version: 565.57.01 CUDA Version: 12.7 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 Off | 00000000:00:07.0 Off | 0 |
| N/A 57C P0 28W / 70W | 1MiB / 15360MiB | 8% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+至此,我们就安装好 GPU 驱动了,系统也能正常识别到 GPU。
这里显示的 CUDA 版本表示当前驱动最大支持的 CUDA 版本。
安装 CUDA Toolkit
对于深度学习程序,一般都要依赖 CUDA 环境,因此需要在机器上安装 CUDA Toolkit。
也是到 NVIDIA CUDA Toolkit 页面下载对应的安装包,选择操作系统和安装方式即可
和安装驱动类似,也是一个 .run 文件。
wget https://developer.download.nvidia.com/compute/cuda/12.6.2/local_installers/cuda_12.6.2_560.35.03_linux.run
sudo sh cuda_12.6.2_560.35.03_linux.run注意:之前安装过驱动了,这里就不再安装驱动(取消选中 Driver),仅安装 CUDA Toolkit 相关组件。
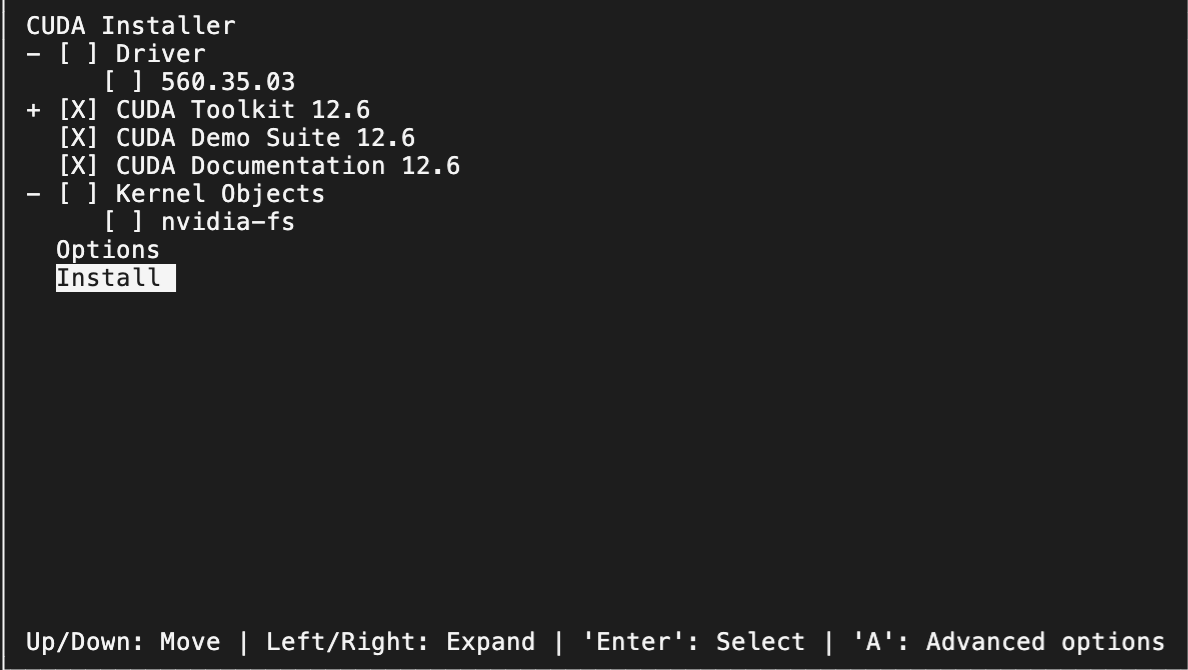
安装完成后输出如下:
===========
= Summary =
===========
Driver: Not Selected
Toolkit: Installed in /usr/local/cuda-12.6/
Please make sure that
- PATH includes /usr/local/cuda-12.6/bin
- LD_LIBRARY_PATH includes /usr/local/cuda-12.6/lib64, or, add /usr/local/cuda-12.6/lib64 to /etc/ld.so.conf and run ldconfig as root
To uninstall the CUDA Toolkit, run cuda-uninstaller in /usr/local/cuda-12.6/bin
***WARNING: Incomplete installation! This installation did not install the CUDA Driver. A driver of version at least 560.00 is required for CUDA 12.6 functionality to work.
To install the driver using this installer, run the following command, replacing <CudaInstaller> with the name of this run file:
sudo <CudaInstaller>.run --silent --driver
Logfile is /var/log/cuda-installer.log根据提示配置下 PATH,将以下两行写入 ~/.bashrc 文件,然后 source ~/.bashrc 使其生效。
export PATH=/usr/local/cuda-12.6/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.6/lib64:$LD_LIBRARY_PATH执行以下命令查看版本,确认安装成功。
root@gpu-demo:~# nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Thu_Sep_12_02:18:05_PDT_2024
Cuda compilation tools, release 12.6, V12.6.77
Build cuda_12.6.r12.6/compiler.34841621_0测试
我们使用一个简单的 Pytorch 程序来检测 GPU 和 CUDA 是否正常。
整个调用链大概是这样的:
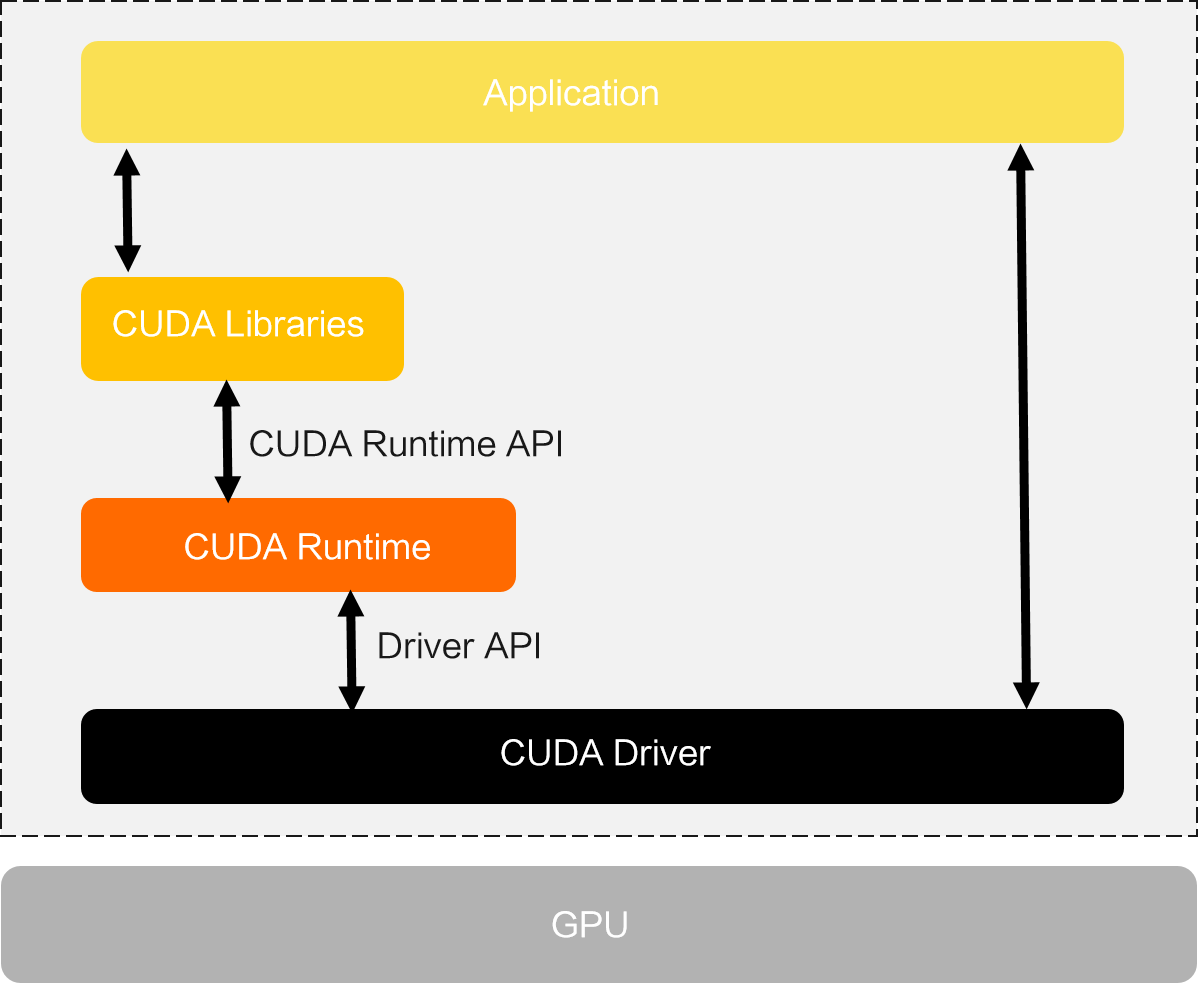
使用下面代码来测试能够正常使用,check_cuda_pytorch.py 内容如下:
import torch
def check_cuda_with_pytorch():
"""检查 PyTorch CUDA 环境是否正常工作"""
try:
print("检查 PyTorch CUDA 环境:")
if torch.cuda.is_available():
print(f"CUDA 设备可用,当前 CUDA 版本是: {torch.version.cuda}")
print(f"PyTorch 版本是: {torch.__version__}")
print(f"检测到 {torch.cuda.device_count()} 个 CUDA 设备。")
for i in range(torch.cuda.device_count()):
print(f"设备 {i}: {torch.cuda.get_device_name(i)}")
print(f"设备 {i} 的显存总量: {torch.cuda.get_device_properties(i).total_memory / (1024 ** 3):.2f} GB")
print(f"设备 {i} 的显存当前使用量: {torch.cuda.memory_allocated(i) / (1024 ** 3):.2f} GB")
print(f"设备 {i} 的显存最大使用量: {torch.cuda.memory_reserved(i) / (1024 ** 3):.2f} GB")
else:
print("CUDA 设备不可用。")
except Exception as e:
print(f"检查 PyTorch CUDA 环境时出现错误: {e}")
if __name__ == "__main__":
check_cuda_with_pytorch()先安装下 PyTorch。
# 可选:创建一个 Python 虚拟环境
python3 -m venv ~/gpu-env
# 激活虚拟环境
source ~/gpu-env/bin/activate
# 安装 PyTorch
pip install torch运行程序。
python3 check_cuda_pytorch.py正常输出应该是这样的:
检查 PyTorch CUDA 环境:
CUDA 设备可用,当前 CUDA 版本是: 12.4
PyTorch 版本是: 2.5.1+cu124
检测到 1 个 CUDA 设备。
设备 0: Tesla T4
设备 0 的显存总量: 14.57 GB
设备 0 的显存当前使用量: 0.00 GB
设备 0 的显存最大使用量: 0.00 GB在容器环境中使用 GPU
为了让 Docker 容器中也能使用 GPU,大致步骤如下:
- 安装 nvidia-container-toolkit 组件
- Docker 配置使用 nvidia-runtime
- 启动容器时增加 --gpu 参数
安装 nvidia-container-toolkit
nvidia-container-toolkit 的主要作用是将 NVIDIA GPU 设备挂载到容器中。兼容生态系统中的任意容器运行时,Docker、containerd、CRI-O 等。
NVIDIA 官方安装文档:nvidia-container-toolkit-install-guide
对于 Ubuntu 系统,安装命令如下:
# 配置仓库地址
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 可选:配置仓库使用实验包
sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
# 从仓库中更新软件包
sudo apt-get update
# 安装 nvidia-container-toolkit
sudo apt-get install -y nvidia-container-toolkit配置使用 nvidia-runtime
如果没安装 Docker 的话可以执行以下命令先安装 Docker。
sudo apt install -y docker.io使用 nvidia-ctk 命令一键配置容器运行时。
sudo nvidia-ctk runtime configure --runtime=docker该命令会修改 /etc/docker/daemon.json 文件,以便 Docker 可以使用 NVIDIA 容器运行时。
{
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
}
}然后重新启动 Docker 守护进程。
sudo systemctl restart docker安装 nvidia-container-toolkit 后,整个调用链如下:当使用 nvidia-container-runtime 启动一个容器时,首先会执行 nvidia-container-runtime-hook。在这个阶段,钩子检查环境变量并决定是否需要挂载 GPU 设备。如果需要,它会通过 nvidia-container-cli 将相关参数传递给运行时,以配置和管理 GPU 的使用。
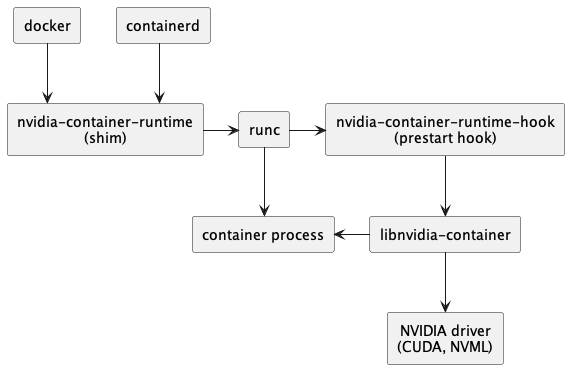
Docker 环境中的 CUDA 调用大概是这样的:
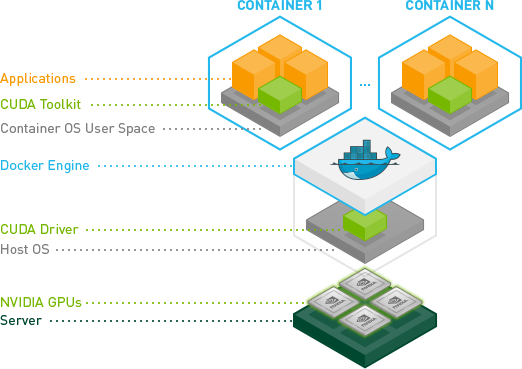
从图中可以看到,CUDA Toolkit 跑到容器里了,因此宿主机上不需要再安装 CUDA Toolkit。(使用一个带 CUDA Toolkit 的镜像即可)
最后我们启动一个 Docker 容器进行测试,其中命令中增加 --gpu 参数来指定要分配给容器的 GPU。--gpu 参数的可选值:
--gpus all:表示将所有 GPU 都分配给该容器--gpus "device=<id>[,<id>...]":对于多 GPU 场景,可以通过 id 指定分配给容器的 GPU,例如--gpu "device=0"表示只分配 0 号 GPU 给该容器。GPU 编号则是通过 nvidia-smi 命令进行查看。
这里我们直接使用一个带 cuda 的镜像来测试,启动该容器并执行 nvidia-smi 命令:
docker run --rm --gpus all nvidia/cuda:12.0.1-runtime-ubuntu22.04 nvidia-smi输出结果如下:
==========
== CUDA ==
==========
CUDA Version 12.0.1
Container image Copyright (c) 2016-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
A copy of this license is made available in this container at /NGC-DL-CONTAINER-LICENSE for your convenience.
Sun Nov 10 08:31:46 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 565.57.01 Driver Version: 565.57.01 CUDA Version: 12.7 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 Off | 00000000:00:07.0 Off | 0 |
| N/A 40C P0 26W / 70W | 1MiB / 15360MiB | 8% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+在 Kubernetes 环境中使用 GPU
参考安装驱动 和 在容器环境中使用 GPU 两个小节分别安装 GPU 驱动和 nvidia-container-toolkit,并配置 Docker 使用 nvidia-runtime。
执行以下命令允许将 GPU 设备作为卷挂载到容器中,使得 Kind 节点能够感知到节点上的 GPU 设备。
sudo nvidia-ctk config --set accept-nvidia-visible-devices-as-volume-mounts=true --in-place使用 Kind 创建一个 Kubernetes 集群。
kind create cluster --name gpu-cluster --config - <<EOF
apiVersion: kind.x-k8s.io/v1alpha4
kind: Cluster
nodes:
- role: control-plane
image: kindest/node:v1.31.2@sha256:18fbefc20a7113353c7b75b5c869d7145a6abd6269154825872dc59c1329912e
# 这里可以指定在容器内可以看到的 GPU 设备
extraMounts:
- hostPath: /dev/null
containerPath: /var/run/nvidia-container-devices/all
EOF
# 有可能需要执行以下命令修复一个错误:https://github.com/NVIDIA/nvidia-docker/issues/614#issuecomment-423991632
docker exec -ti gpu-cluster-control-plane ln -s /sbin/ldconfig /sbin/ldconfig.real由于我们前面已经在裸机上安装了 GPU 驱动,因此可以在安装 gpu-operator 时跳过安装 GPU 驱动。
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia
helm repo update
helm install --wait --generate-name \
-n gpu-operator --create-namespace \
nvidia/gpu-operator \
--set driver.enabled=false安装完成后,可以看到 gpu-operator 的相关 pod 已经正常运行。
root@gpu-demo:~# kubectl get pod -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-bt46s 1/1 Running 0 71s
gpu-operator-1731231396-node-feature-discovery-gc-796f79c4plgvz 1/1 Running 0 109s
gpu-operator-1731231396-node-feature-discovery-master-8694lfqb4 1/1 Running 0 109s
gpu-operator-1731231396-node-feature-discovery-worker-fmqqf 1/1 Running 0 103s
gpu-operator-54898ddd57-gggx2 1/1 Running 0 109s
nvidia-container-toolkit-daemonset-5f6mc 1/1 Running 0 73s
nvidia-cuda-validator-68cww 0/1 Completed 0 20s
nvidia-dcgm-exporter-jwr2f 1/1 Running 0 72s
nvidia-device-plugin-daemonset-7cqrs 1/1 Running 0 72s
nvidia-operator-validator-s4ss7 1/1 Running 0 73s在 Kubernetes 创建 Pod 要使用 GPU 资源很简单,和 cpu、memory 等常规资源一样,在 resource 中申请即可。
比如,下面这个 YAML 里面我们就通过 resource.limits 申请了该 Pod 要使用 1 个 GPU。
kubectl apply -f - << EOF
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvcr.io/nvidia/k8s/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04"
resources:
limits:
nvidia.com/gpu: 1
EOF启动后,查看日志,正常应该会打印测试通过的信息。
root@gpu-demo:~# kubectl logs cuda-vectoradd
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done完整的脚本可以在这里找到:https://github.com/cr7258/hands-on-lab/blob/main/ai/gpu/setup/create-gpu-cluster.sh
参考资料
- Tutorial: K8s Kind with GPUs
- GPU 环境搭建指南:如何在裸机、Docker、K8s 等环境中使用 GPU
- GPU 环境搭建指南:使用 GPU Operator 加速 Kubernetes GPU 环境搭建
- NVIDIA Cloud Native Technologies - Architecture Overview
- NVIDIA/nvkind
GPU 虚拟化
HAMi
HAMi 全称是:Heterogeneous AI Computing Virtualization Middleware,HAMi 给自己的定位或者希望是做一个异构算力虚拟化平台。HAMI 是原第四范式的 k8s-vgpu-scheduler, 这次改名 HAMi 同时也将核心的 vCUDA 库 libvgpu.so 也开源了。
使用 HAMi 最大的一个功能点就是可以实现 GPU 的细粒度的隔离,可以对 core 和 memory 使用 1% 级别的隔离。
安装 HAMi
添加 HAMI 的 Helm 仓库。
helm repo add hami-charts https://project-hami.github.io/HAMi/查看 Kubernetes 的版本。
kubectl version安装 HAMI 时需要根据集群版本(上一条指令的结果)指定调度器镜像版本,例如集群版本为 v1.31.2,则可以使用以下命令进行安装:
helm install hami hami-charts/hami --set scheduler.kubeScheduler.imageTag=v1.31.2 -n kube-systemHAMI 的 device-plugin 默认会运行在有 gpu=on 标签的节点上,可以通过以下命令给节点打上标签。
kubectl label node gpu-cluster-control-plane gpu=on看到 vgpu-device-plugin 与 vgpu-scheduler 两个 Pod 状态为 Running 即为安装成功。
root@gpu-demo:~# kubectl get pod -n kube-system | grep hami
hami-device-plugin-sz4s7 2/2 Running 0 6m31s
hami-scheduler-74b5f7df7-m67ff 2/2 Running 0 12m验证效果
HAMI 默认会为将一个 GPU 虚拟为 10 个 vGPU。
root@gpu-demo:~# kubectl get node gpu-cluster-control-plane -oyaml | grep capacity -A 7
capacity:
cpu: "4"
ephemeral-storage: 40901312Ki
hugepages-1Gi: "0"
hugepages-2Mi: "0"
memory: 14951736Ki
nvidia.com/gpu: "10"
pods: "110"使用以下 YAML 创建来 Pod 使用 GPU。注意:虽然 vGPU 被虚拟为 10 个,但是 1 个 Pod 申请的 vGPU 数量不能超过物理的 GPU 数,不过可以为多个 Pod 分别申请 1 个 vGPU。
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
containers:
- name: ubuntu-container
image: ubuntu:18.04
command: ["bash", "-c", "sleep 86400"]
resources:
limits:
nvidia.com/gpu: 1 # 请求 1 个 vGPU
nvidia.com/gpumem: 3000 # 每个 vGPU 申请 3000m 显存 (可选,整数类型)
nvidia.com/gpucores: 30 # 每个 vGPU 的算力为 30% 实际显卡的算力 (可选,整数类型)可以看到显存被限制为 3000MiB,虽然实际显存是 15360MiB。
root@gpu-demo:~# kubectl exec -it gpu-pod -- nvidia-smi
[HAMI-core Msg(23:140237381220160:libvgpu.c:836)]: Initializing.....
Sun Nov 10 10:26:46 2024
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 565.57.01 Driver Version: 565.57.01 CUDA Version: 12.7 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Tesla T4 Off | 00000000:00:07.0 Off | 0 |
| N/A 33C P8 14W / 70W | 0MiB / 3000MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
[HAMI-core Msg(23:140237381220160:multiprocess_memory_limit.c:468)]: Calling exit handler 23