ILM 索引生命周期管理
本系列 Elastic Stack 实战教程总共涵盖 5 个实验,目的是帮助初学者快速掌握 Elastic Stack 的基本技能。
- 实验 1:Elastic Stack 8 快速上手
- 实验 2:ILM 索引生命周期管理
- 实验 3:快照备份与恢复
- 实验 4:使用 Fleet 管理 Elastic Agent 监控应用
- 实验 5:Elasticsearch Java API Client 开发
1 索引生命周期介绍
索引生命周期管理 (Index Lifecycle Management, ILM) 是在 Elasticsearch 在 6.6(公测版)首次引入并在 6.7 版正式推出的一项功能。ILM 旨在帮助用户更方便地管理时序数据(例如日志,指标等)。时序数据有如下几个典型的特点:
- 随着时间的推移,数据的价值在逐渐降低。
- 数据量非常大。
- 数据追加写入,通常不会修改旧数据。
随着数据量的不断增大,我们需要对索引进行一定的维护管理甚至是删除清理。利用 ILM 策略我们针对索引不同阶段对数据读写的要求,将索引分配到合适的节点上,从而更好地利用机器的资源:
- 例如最新需要频繁读写的数据,可以保存到 SSD 硬盘的节点上。
- 对于较旧的数据,可以保存到机械硬盘的节点上。
- 对于归档数据,可以保持到大容量廉价硬盘的节点上。
- 当数据超过一定的时间,不再需要时,可以将该数据删除。
ILM 将一个索引的生命周期定义为了 5 个阶段,除了 Hot 阶段以外,其他阶段都是可选的。
| 阶段 | 介绍 |
|---|---|
| Hot | 索引正在被实时地写入和查询,可根据索引的文档数、大小、时长决定是否调用 Rollover API 来滚动创建新的索引。 |
| Warm | 索引不再被更新,但仍在被查询。 |
| Cold | 索引不再被更新,并且很少被查询,如果这些查询比较慢也没关系。 |
| Frozen | 索引不再被更新,并且很少被查询,如果这些查询非常慢也没关系。 |
| Delete | 不再需要索引,可以安全地删除。 |
不同的阶段只允许执行相应的 Action,具体如下表所示。
| 阶段 | Set Priority | Unfollow | Rollover | Read-Only | Shrink | Force Merge | Searchable Snapshot | Allocate | Migrate | Wait For Snapshot | Delete |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Hot | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ |
| Warm | ✅ | ✅ | ❌ | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ | ❌ | ❌ |
| Cold | ✅ | ✅ | ❌ | ✅ | ❌ | ❌ | ✅ | ✅ | ✅ | ❌ | ❌ |
| Frozen | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ | ❌ | ❌ | ❌ | ❌ |
| Delete | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ | ✅ | ✅ |
常用的 Action 如下。
| 动作 | 介绍 |
|---|---|
| Rollover | 根据索引的文档数、大小、时长决定是否调用 Rollover API 来滚动创建新的索引。 |
| Shrink | 减少索引的主分片数。 |
| Force Merge | 段合并,可以减少索引段的数量并提高检索速度。段合并的时候会将那些旧的已删除文档从文件系统中清除。 |
| Allocate | 修改索引的副本分片数。 |
| Read-Only | 将索引设置为只读。 |
| Delete | 删除索引。 |
2 部署冷热分层集群
在 Elasticsearch 7.10 中引入了 data tiers(数据层)的概念,对数据节点类型做进一步的细分,分为 data_content, data_host, data_warm, data_cold, data_frozen,同一数据层的节点通常拥有相同硬件配置和性能。不同数据层的定义如下:
- 内容层(content tier): 内容层往往存储常态化的数据,与时间序列数据不同,这类数据的价值随着时间的推移相对保持恒定,例如产品目录或者商品种类。
- 热层(hot tier): 热层存储最新的时间序列数据,这类数据也是被查询最多的数据,因此热层中的节点在写入和读取时都需要快速,因此热层的节点通常拥有更好的 CPU、内存资源和更快的存储(例如 SSD 固态硬盘)。
- 温层(warm tier): 一旦查询查询时间序列数据的频率开始低于热层中最近写入的数据,那么便可以将这些数据转移至温层。温层通常保留最近几周的数据,一般不会再对这些数据进行更新,温层的节点不需要像热层中的节点一样快。
- 冷层(cold tier): 冷层存储访问频率较低的数据,我们通常会将冷层的数据设置为只读的,并且随着数据过渡到冷层,还可以对其进行压缩和去副本以节省存储空间。
- 冻结层(frozon tier): 一旦数据不再被查询,便可以将数据从冷层移动到冻结层。在冻结层中可以选择以挂载索引的方式将数据存储在快照存储库中,可以省去副本的存储空间,当需要搜索时,再去快照存储库中提取数据,因此查询的速度通常较慢。
需要确保集群中至少有一个 data_hot 和 data_content 节点,即使它们是同一个节点,否则新索引将无法被分配。 新创建的索引默认将分配到 data_content 节点上。
在本实验中,我们将部署一个由 4 个节点组成的冷热分离架构的 Elasticsearch 集群,节点的角色分配如下。
| 节点 | 角色 | 说明 |
|---|---|---|
| es01 | master, data_content, data_hot | 内容层,热层 |
| es02 | master, data_content, data_hot | 内容层,热层 |
| es03 | master, data_warm | 温层 |
| es04 | master, data_cold | 冷层 |
首先执行以下命令修改系统参数以满足 Elasticsearch 的运行条件。
# 增加进程可使用的最大内存映射区域数
cat >> /etc/sysctl.conf << EOF
vm.max_map_count=262144
EOF
sysctl -p
# 增加进程可使用的最大文件描述符数量
cat >> /etc/security/limits.conf << EOF
elastic - nofile 65535
EOF
ulimit -n 65535为了方便实验,本节采用 Docker Compose 的方式快速部署 Elasticsearch 集群。执行如下命令,安装 Docker 和 Docker Compose。
curl -sSL https://get.daocloud.io/docker | sh
apt install -y docker-compose执行如下命令,获取 docker-compose.yml 配置文件,并在后台启动 Elasticsearch 集群。
apt install -y git
git clone https://gitee.com/cr7258/elastic-lab.git
cd elastic-lab/2_ilm/
docker-compose up -d执行 docker-compose ps 命令查看容器运行状态,其中 2ilm_setup_1 容器是用于创建证书以及设置 elastic 和 kibana_system 用户密码的,执行完毕后会自动退出,我们需要确保其他容器处于 Up 状态。

3 设置 ILM 策略
浏览器输入 http://<ESC 公网 IP>:5601 访问 Kibana 界面。输入用户名 elastic,密码 elastic123,点击 Login in。其中密码是在 elastic-lab/2_ilm/.env 文件中设置的。

点击 Management -> Dev Tools -> Console,打开 Kibana Console 界面。ILM 服务会在后台定期轮询执行 Policy,默认的时间间隔为 10 分钟,为了测试更快地看到效果,这里将其修改为 1 秒。
PUT _cluster/settings
{
"persistent": {
"indices.lifecycle.poll_interval":"1s"
}
}接下来设置 ILM 策略,包含以下 4 个阶段:
- Hot 阶段:超过 5 个文档以后 rollover 创建新的索引。
- Warm 阶段:60s 后进入 warm 阶段,将副本分片数缩减为 0。
- Cold 阶段:120s 后进入 cold 阶段,将索引设置为只读。
- Delete 阶段:180s 后进入 delete 阶段,删除索引。

PUT _ilm/policy/log-ilm-policy
{
"policy": {
"phases": {
"hot": {
"min_age": "0s",
"actions": {
"rollover": {
"max_docs": 5 // 超过 5 个文档以后 rollover 创建新的索引
},
"set_priority": {
"priority": 100 // 优先级最高,当节点重启后优先恢复 hot 阶段的索引
}
}
},
"warm": {
"min_age": "60s", // 60s 后进入 warn 阶段
"actions": {
"allocate": {
"number_of_replicas": 0 // 将副本分片数缩减为 0
},
"set_priority": {
"priority": 50
}
}
},
"cold": {
"min_age": "120s", // 120s 后进入 cold 阶段
"actions": {
"readonly" : {}, // 将索引设置为只读
"set_priority": {
"priority": 0
}
}
},
"delete": {
"min_age": "180s", // 180s 后删除索引
"actions": {
"delete": {}
}
}
}
}
}4 设置索引模板
创建索引模板,匹配 log-index- 开头的索引,关联 ILM 策略和别名,新索引的主分片数和副本分片数都设置为 1。索引模板是预先定义好的在创建新索引时自动应用的模板,在索引模板中可以定义在创建索引时为索引添加的别名、设置、字段映射以及索引应用的 ILM 策略等内容。
PUT _index_template/log-template
{
"index_patterns" : [
"log-index-*" // 通配符匹配索引
],
"template": {
"settings" : {
"index" : {
"lifecycle" : {
"name" : "log-ilm-policy", // 应用 ILM 策略
"rollover_alias" : "log-index" // 指定 rollover 别名
},
"number_of_shards" : "1", // 主分片数
"number_of_replicas" : "1" // 副本分片数
}
}
}
}5 创建符合模板的起始索引
创建第一个索引 log-index-000001,设置索引别名为 log-index,后续在 rollover 滚动更新索引时,索引名会根据最后的序号递增,例如 log-index-000002,log-index-000003,log-index-000004 ...。is_write_index 参数设置为 true 表示往别名发送的写请求将发送到 log-index-000001 索引上。当发生 Rollover 时,Elasticsearch 会自动将新创建的索引的 is_write_index 参数设置为 true,同时将旧索引的 is_write_index 参数设置为 false,以确保往别名写入时只写入同一个索引。
PUT log-index-000001
{
"aliases": {
"log-index": {
"is_write_index": true
}
}
}查看别名 log-index,可以看到该别名下目前只有 1 个索引 log-index-000001,该索引处于可写的状态,并且应用了我们设置的 ILM 策略。当新建索引时,默认情况下,Elasticsearch 会将 index.routing.allocation.include._tier_preference 参数设置为 data_content,以将索引分片自动分配给内容层。
GET log-index
# 返回结果
{
"log-index-000001" : {
"aliases" : {
"log-index" : {
"is_write_index" : true // 可写
}
},
"mappings" : { },
"settings" : {
"index" : {
"lifecycle" : { // 应用 ILM 策略
"name" : "log-ilm-policy",
"rollover_alias" : "log-index"
},
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content" // 分片分配到内容层上
}
}
},
"number_of_shards" : "1",
"provided_name" : "log-index-000001",
"creation_date" : "1657374734018",
"priority" : "100",
"number_of_replicas" : "1",
"uuid" : "kOXmUzVlRRmTZJfBxolpmg",
"version" : {
"created" : "8020399"
}
}
}
}
}6 插入数据,观察效果
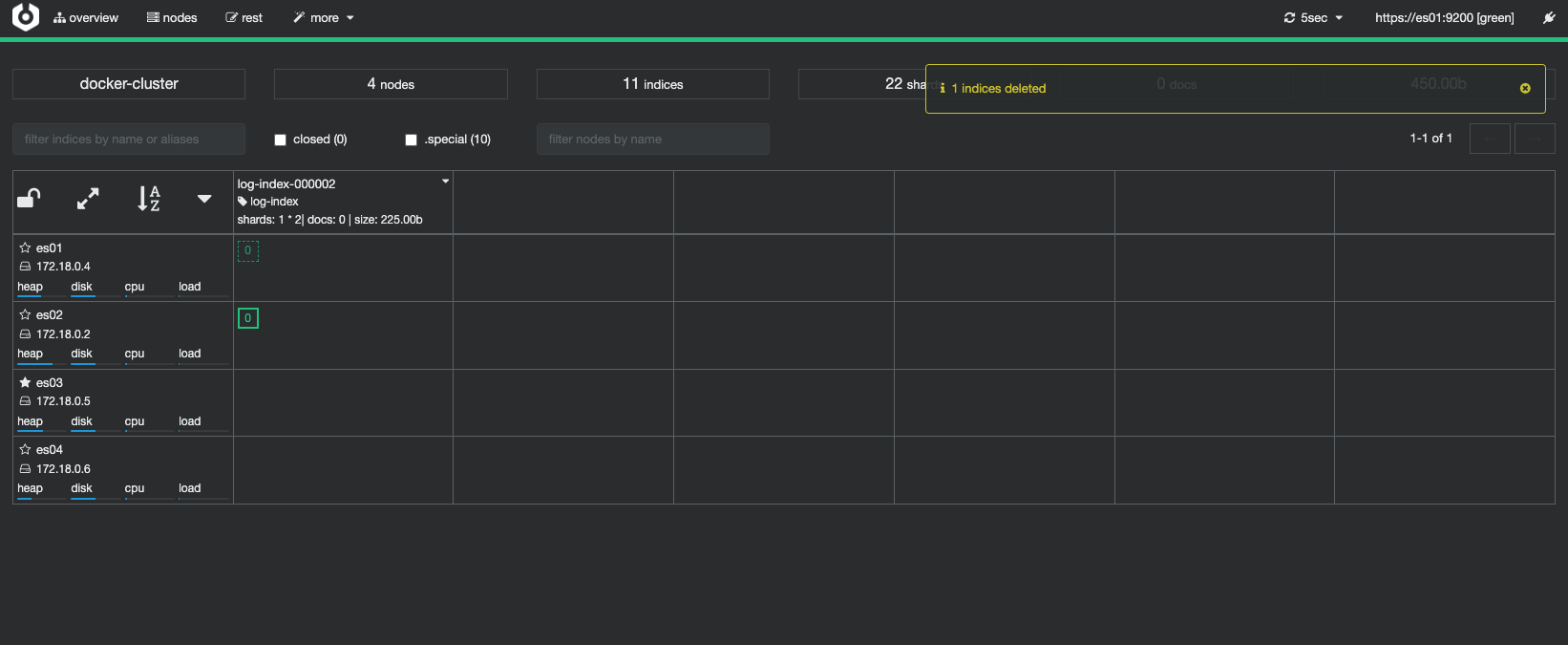
浏览器输入 http://<ESC 公网 IP>:9000 访问 Cerebro,在 Node address 输入框内填入 https://es01:9200,然后点击 Connect 连接 Elasticsearch 集群。
 输入用户名 elastic,密码 elastic123,点击 Authenticate。
输入用户名 elastic,密码 elastic123,点击 Authenticate。 
往索引中插入 5 条数据,然后观察 ILM 策略的执行效果。
POST log-index/_bulk
{"index":{}}
{"name":"Erlend","age":16}
{"index":{}}
{"name":"Brynjar","age":18}
{"index":{}}
{"name":"Fox","age":18}
{"index":{}}
{"name":"Frank","age":23}
{"index":{}}
{"name":"Sam","age":18}
// 手动触发段合并,让 Elasticsearch 更快监测到文档数量的变化
POST log-index/_forcemerge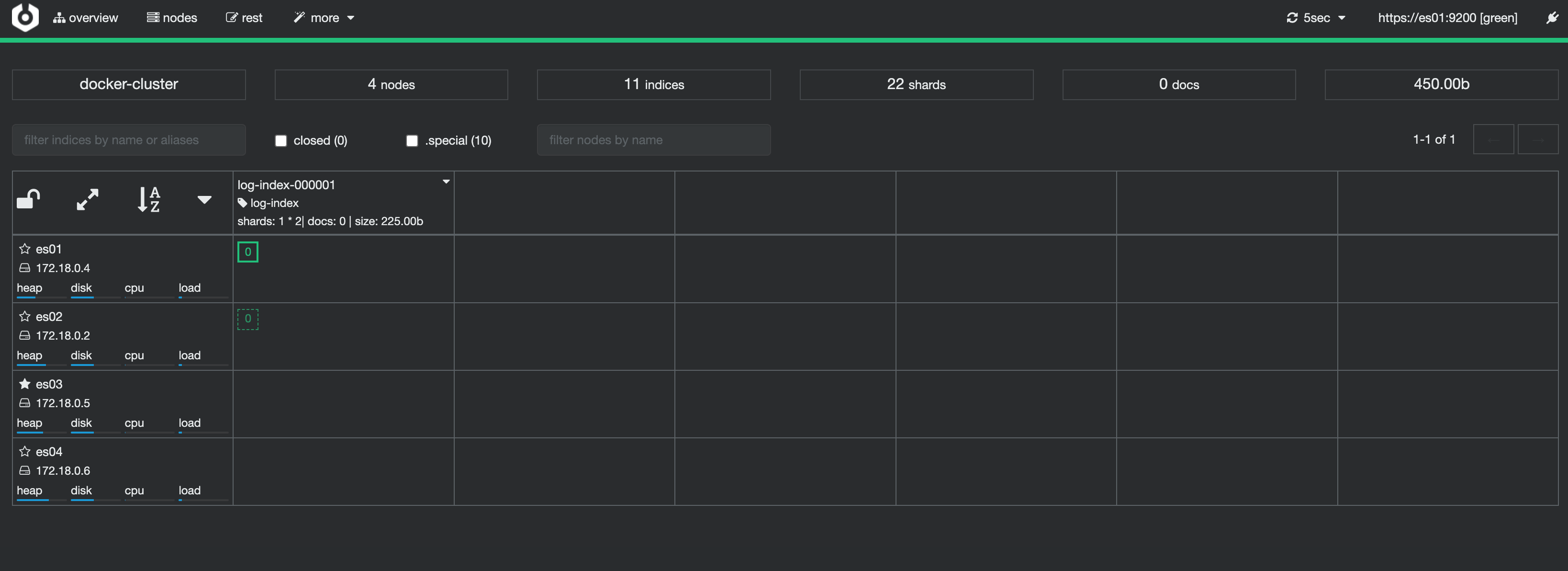 等待一会 Elasticsearch 发现 log-index-000001 索引中的文档数达到 5 个,会触发 Rollover,创建新的索引 log-index-000002。
等待一会 Elasticsearch 发现 log-index-000001 索引中的文档数达到 5 个,会触发 Rollover,创建新的索引 log-index-000002。
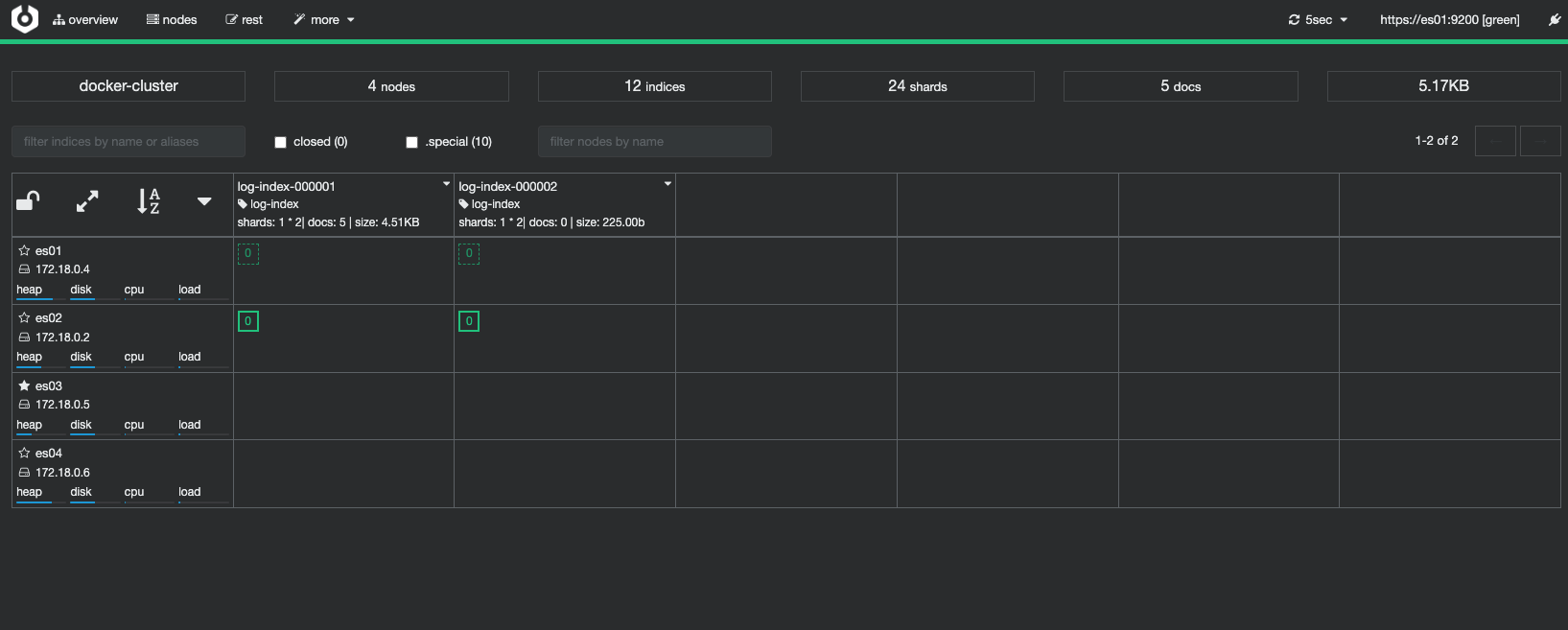
往别名发起的写入请求将会写入 log-index-000002 索引中。当然此时你仍然可以指定往 log-index-000001 索引中写入数据。
GET log-index
# 返回结果
{
"log-index-000001" : {
"aliases" : {
"log-index" : {
"is_write_index" : false // 被改为 false 了
}
},
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"settings" : {
"index" : {
"lifecycle" : {
"name" : "log-ilm-policy",
"rollover_alias" : "log-index",
"indexing_complete" : "true"
},
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "log-index-000001",
"creation_date" : "1657374734018",
"priority" : "100",
"number_of_replicas" : "1",
"uuid" : "kOXmUzVlRRmTZJfBxolpmg",
"version" : {
"created" : "8020399"
}
}
}
},
"log-index-000002" : {
"aliases" : {
"log-index" : {
"is_write_index" : true // 往别名发起的写入请求将发给 log-index-000002 索引
}
},
"mappings" : { },
"settings" : {
"index" : {
"lifecycle" : {
"name" : "log-ilm-policy",
"rollover_alias" : "log-index"
},
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "log-index-000002",
"creation_date" : "1657374971168",
"priority" : "100",
"number_of_replicas" : "1",
"uuid" : "tT1hbzQxQH2Ms5luQki6gw",
"version" : {
"created" : "8020399"
}
}
}
}
}等待 60s,log-index-000001 索引进入 Warm 阶段,索引分片移动到 es03 节点上,此时只保留了主分片,副本分片缩减为 0。

此时发现 log-index-000001 索引的 index.routing.allocation.include._tier_preference 参数被修改为了 data_warm,data_hot,当存在 data_warm 角色的节点,则将索引分配给温层;如果不存在 data_warm 角色的节点,则将索引分配给热层。
GET log-index
# 返回结果
{
"log-index-000001" : {
"aliases" : {
"log-index" : {
"is_write_index" : false
}
},
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"settings" : {
"index" : {
"lifecycle" : {
"name" : "log-ilm-policy",
"rollover_alias" : "log-index",
"indexing_complete" : "true"
},
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_warm,data_hot" // 优先分配到温层
}
}
},
"number_of_shards" : "1",
"provided_name" : "log-index-000001",
"creation_date" : "1657374734018",
"priority" : "50",
"number_of_replicas" : "0",
"uuid" : "kOXmUzVlRRmTZJfBxolpmg",
"version" : {
"created" : "8020399"
}
}
}
},
"log-index-000002" : {
"aliases" : {
"log-index" : {
"is_write_index" : true
}
},
"mappings" : { },
"settings" : {
"index" : {
"lifecycle" : {
"name" : "log-ilm-policy",
"rollover_alias" : "log-index"
},
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "log-index-000002",
"creation_date" : "1657374971168",
"priority" : "100",
"number_of_replicas" : "1",
"uuid" : "tT1hbzQxQH2Ms5luQki6gw",
"version" : {
"created" : "8020399"
}
}
}
}
}等待 120s,log-index-000001 索引进入 Cold 阶段,索引分片移动到 es04 节点上,此时索引被设置为只读状态。

此时发现 log-index-000001 索引的 index.routing.allocation.include._tier_preference 参数被修改为了 data_cold,data_warm,data_hot,索引将会被优先分配到冷层,如果没有 data_cold 角色的节点,再依次考虑分配到温层或者热层。
GET log-index
# 返回结果
{
"log-index-000001" : {
"aliases" : {
"log-index" : {
"is_write_index" : false
}
},
"mappings" : {
"properties" : {
"age" : {
"type" : "long"
},
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
},
"settings" : {
"index" : {
"lifecycle" : {
"name" : "log-ilm-policy",
"rollover_alias" : "log-index",
"indexing_complete" : "true"
},
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_cold,data_warm,data_hot" // 优先分配到冷层
}
}
},
"number_of_shards" : "1",
"blocks" : {
"write" : "true"
},
"provided_name" : "log-index-000001",
"creation_date" : "1657374734018",
"priority" : "0",
"number_of_replicas" : "0",
"uuid" : "kOXmUzVlRRmTZJfBxolpmg",
"version" : {
"created" : "8020399"
}
}
}
},
"log-index-000002" : {
"aliases" : {
"log-index" : {
"is_write_index" : true
}
},
"mappings" : { },
"settings" : {
"index" : {
"lifecycle" : {
"name" : "log-ilm-policy",
"rollover_alias" : "log-index"
},
"routing" : {
"allocation" : {
"include" : {
"_tier_preference" : "data_content"
}
}
},
"number_of_shards" : "1",
"provided_name" : "log-index-000002",
"creation_date" : "1657374971168",
"priority" : "100",
"number_of_replicas" : "1",
"uuid" : "tT1hbzQxQH2Ms5luQki6gw",
"version" : {
"created" : "8020399"
}
}
}
}
}等待 180s,log-index-000001 索引被删除。至此完成了整个索引生命周期流程。