使用 NVIDIA Dynamo 部署 PD 分离推理服务
1 Dynamo 介绍
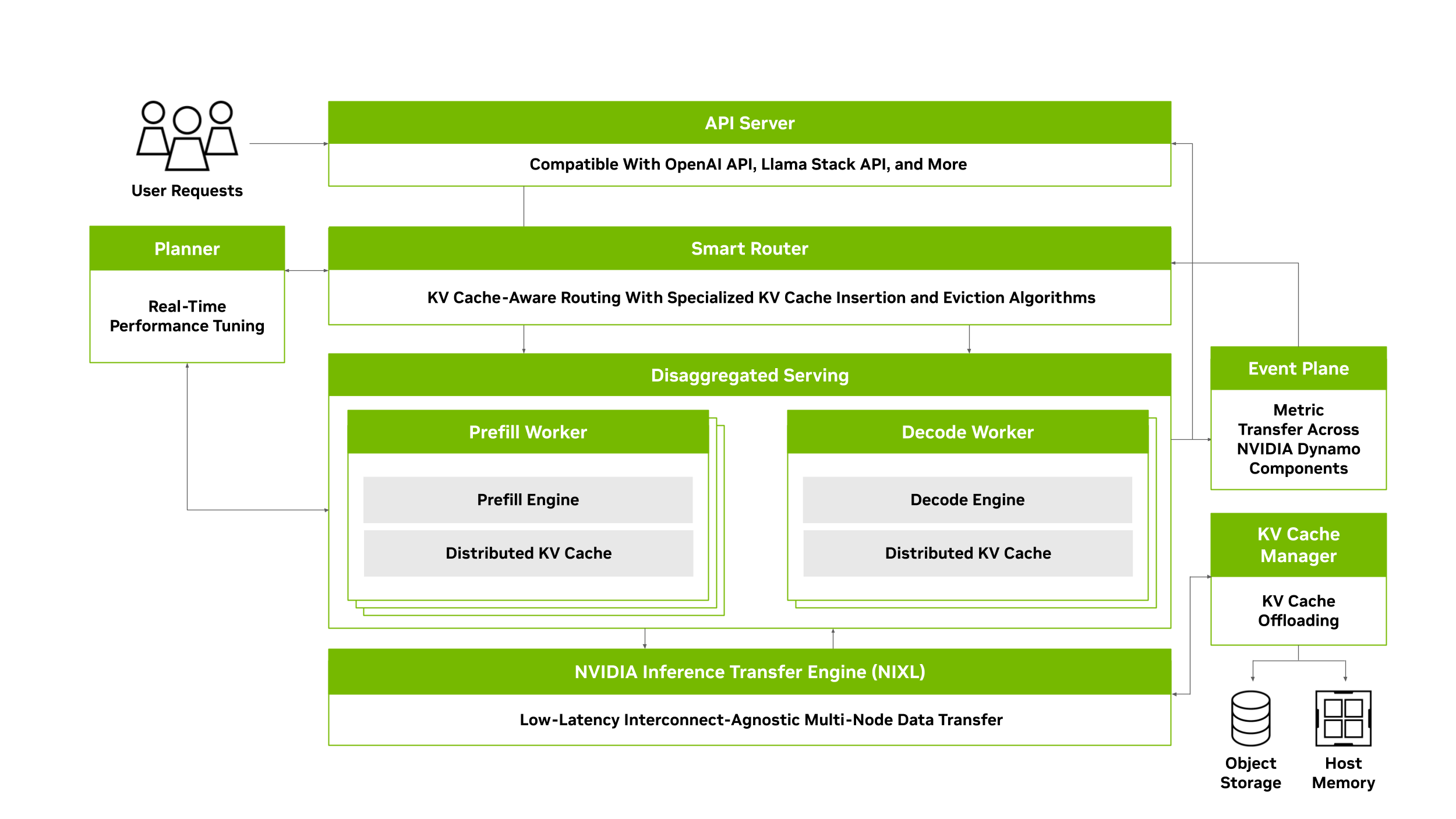
NVIDIA Dynamo 是一个开源的模块化推理框架,用于在分布式环境上实现生成式 AI 模型的服务化部署。Dynamo 通过动态资源调度、智能路由、内存优化与高速数据传输,无缝扩展大型 GPU 集群之间的推理工作负载。
Dynamo 采用推理引擎无关的设计(支持 TensorRT-LLM、vLLM、SGLang 等),包括以下 4 个核心组件:
- NVIDIA Dynamo Planner:一个智能规划和调度引擎,用于监控分布式推理中的容量与延迟,并在 prefill 与 decode 阶段之间灵活分配 GPU 资源,以最大化吞吐量和效率。Planner 会持续跟踪关键的 GPU 容量指标,并结合应用的 SLO(如 TTFT 和 ITL),智能决策是否采用分离式推理,或是否需要为 prefill/decode 阶段动态增加更多 GPU。
- NVIDIA Dynamo Smart Router:KV cache 感知的路由引擎,可在分布式推理环境中将请求转发到最佳的节点,从而最大限度减少 KV cache 的重复计算开销。
- NVIDIA Dynamo Distributed KV Cache Manager:通过将较旧或低频访问的 KV cache 卸载到更低成本的存储(如 CPU 内存、本地存储或对象存储等),大幅降低 GPU 内存占用。借助这种分层管理,开发者既能保留大规模 KV cache 重用的优势,又能释放宝贵的 GPU 资源,从而有效降低推理计算成本。
- NVIDIA Inference Transfer Library (NIXL):高效的推理数据传输库,可加速 GPU 之间以及异构内存与存储之间的 KV cache 传输。通过减少同步开销和智能批处理,NIXL 显著降低了分布式推理中的通信延迟,使得在 prefill/decode 分离部署时,prefill 节点也能在毫秒级将大批量的 KV cache 传输至 decode 节点,从而避免跨节点数据交换成为性能瓶颈。
在这篇文章中,我们将介绍如何安装和运行 Dynamo,包括快速开始、PD 分离部署,以及在 Kubernetes 环境中的实践。快速开始示例只需 1 个 GPU,而 PD 分离部署示例则需要 2 个 GPU。
2 安装依赖
在启动 Dynamo 之前,需要确保系统已经安装了 Docker、NVIDIA GPU Driver、CUDA Toolkit、NVIDIA Container Toolkit 等依赖。以下安装步骤基于 Ubuntu 操作系统,其他 Linux 发行版请参考相应的官方文档。
2.1 安装 Docker
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "${UBUNTU_CODENAME:-$VERSION_CODENAME}") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
sudo apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin2.2 安装 NVIDIA GPU Driver 和 CUDA Toolkit
wget https://developer.download.nvidia.com/compute/cuda/12.6.2/local_installers/cuda_12.6.2_560.35.03_linux.run
sudo sh cuda_12.6.2_560.35.03_linux.run --silent
cat << EOF >> ~/.bashrc
export PATH=/usr/local/cuda-12.6/bin:\$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-12.6/lib64:\$LD_LIBRARY_PATH
EOF
source ~/.bashrc2.3 安装 NVIDIA Container Toolkit:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sed -i -e '/experimental/ s/^#//g' /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
export NVIDIA_CONTAINER_TOOLKIT_VERSION=1.17.8-1
sudo apt-get install -y \
nvidia-container-toolkit=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
nvidia-container-toolkit-base=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container-tools=${NVIDIA_CONTAINER_TOOLKIT_VERSION} \
libnvidia-container1=${NVIDIA_CONTAINER_TOOLKIT_VERSION}
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker2.4 安装 Python 依赖
Dynamo 推荐使用 uv 作为 Python 包管理器,执行以下命令安装 uv:
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env安装 Python 开发工具和编译工具:
sudo apt-get install -y python3.12-dev build-essential3 运行 Dynamo
3.1 快速开始
首先克隆仓库:
git clone https://github.com/ai-dynamo/dynamo.git
cd dynamo在 Dynamo 框架中,跨节点通信使用的是 NIXL。NIXL 启动时会向 etcd 注册以实现节点间的自动发现,而 NATS 服务则主要用于 prefill 与 decode worker 之间的消息传递。因此,在部署推理服务之前,需要先完成 etcd 和 NATS 的部署。执行以下命令,通过 docker-compose 启动 etcd 和 NATS 服务:
docker compose -f deploy/docker-compose.yml up -dDynamo 为每个支持的引擎(TensorRT-LLM、vLLM、SGLang 等)单独发布了对应的 Python wheel。这里以 vLLM 为例,执行以下命令安装依赖:
# 创建 Python 虚拟环境
uv venv venv
source venv/bin/activate
uv pip install pip
# 安装 Dynamo vLLM
uv pip install "ai-dynamo[vllm]"执行以下命令启动 Dynamo 的 vLLM worker,使用 Qwen/Qwen3-0.6B 模型进行推理:
python -m dynamo.vllm --model Qwen/Qwen3-0.6B然后启动 Dynamo 的 frontend,一个用 Rust 编写的高性能 OpenAI 兼容 HTTP API 服务:
python -m dynamo.frontend --http-port 8000接下来,你可以使用 curl 命令发送请求,或通过任意兼容 OpenAI 的客户端程序或库进行调用。
curl -X POST http://localhost:8000/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "Qwen/Qwen3-0.6B",
"messages": [
{ "role": "user", "content": "Tell me a story about a brave cat" }
],
"stream": false,
"max_tokens": 1028
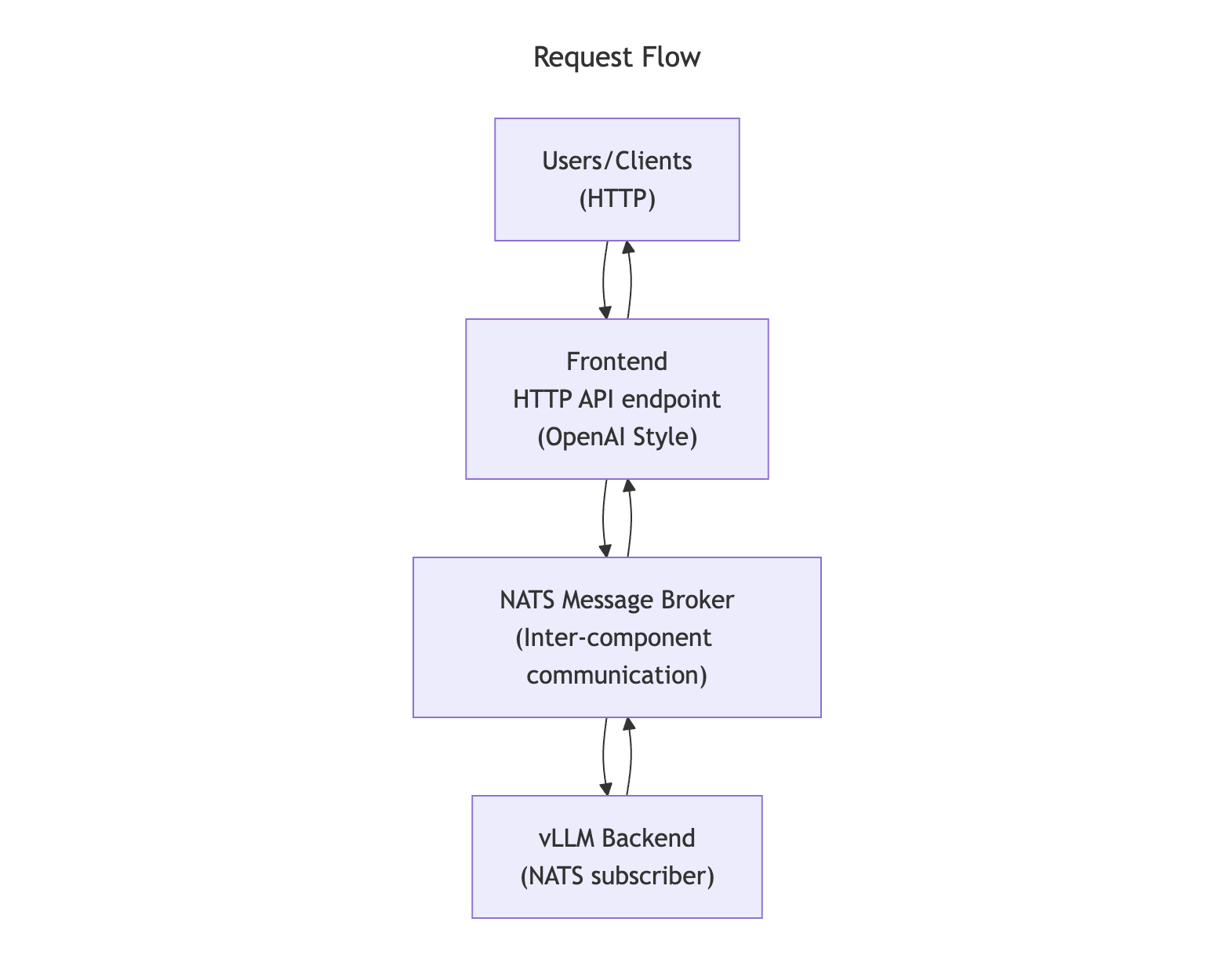
}'在幕后,当你向 frontend 发送一个 HTTP 请求时,会经历以下过程:
- 请求封装:frontend 会将你的 HTTP 请求封装为带有路由元数据的标准化内部格式。
- NATS Subject 解析:frontend 使用在 etcd 中发现的服务信息,解析出合适的 NATS 端点。
- 消息分发:请求被发布到对应的 NATS subject,并由目标 vLLM backend 接收。
- 响应流式传输:vLLM backend 执行请求,并通过 NATS 将响应以流的形式返回,frontend 再将其转换回标准的 HTTP 响应。
3.2 PD 分离(Prefill-Decode Disaggregation)
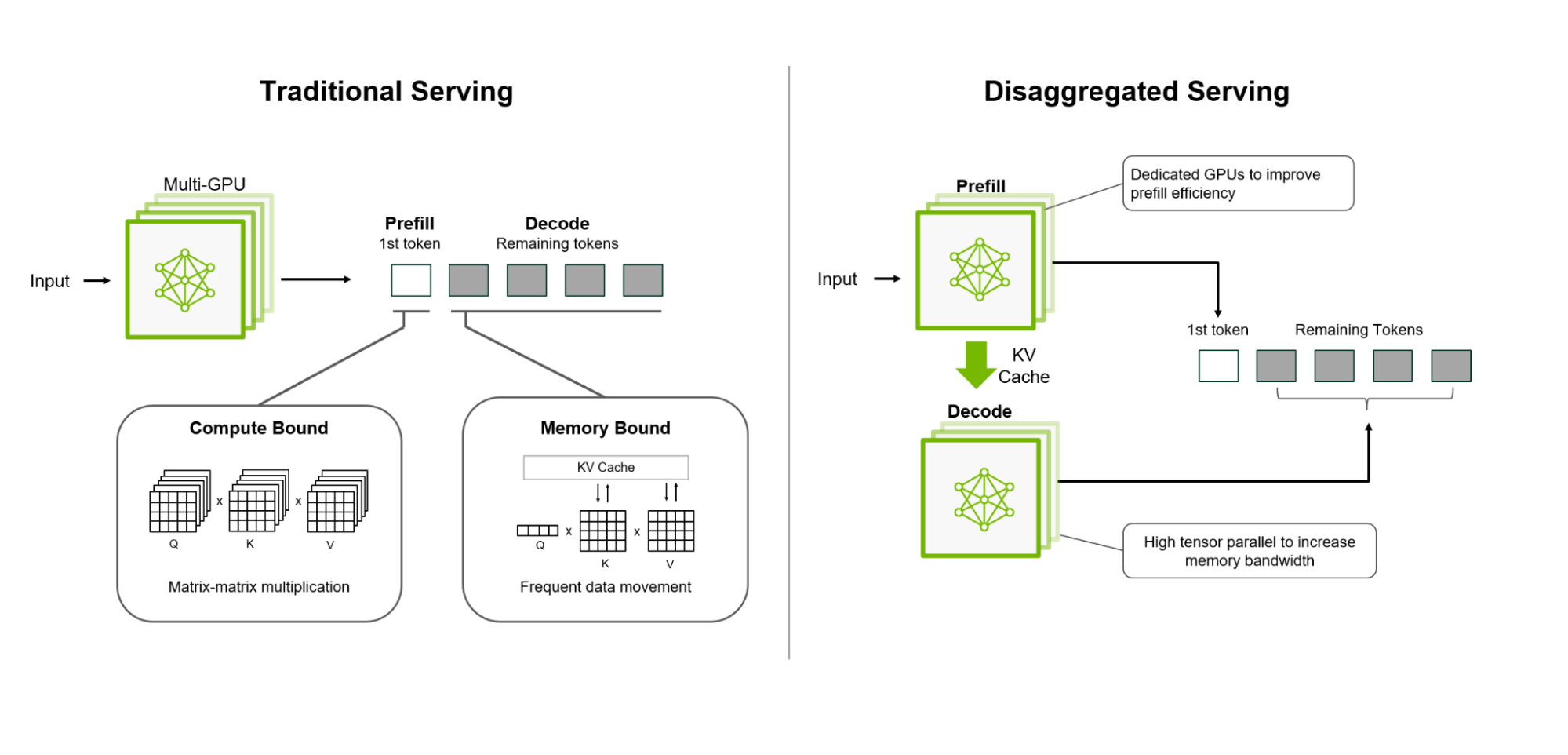
LLM 请求的 prefill 阶段和 decode 阶段在计算特性和内存占用上有显著差异。将这两个阶段拆分到专门的 LLM 引擎中,可以实现更合理的硬件资源分配、更好的可扩展性以及整体性能提升。比如,在内存受限的 decode 阶段使用更大的 TP(tensor parallelism),而在计算密集的 prefill 阶段使用较小的 TP,就能让两个阶段都高效执行。此外,对于长上下文请求,将其 prefill 阶段交给专门的 prefill 引擎,可以避免正在进行的 decode 请求被这些长 prefill 阻塞,从而保持系统的高效处理。
一个请求的分离式执行主要包括三个步骤:
- prefill worker 计算 prefill 阶段并生成 KV cache;
- prefill worker 将 KV cache 传输给 decode worker;
- decode worker 计算 decode 阶段。
不过,并非所有请求的 prefill 阶段都需要在远程 prefill worker 上执行。如果 prefill 较短,或者 decode worker 有较高的 prefix cache 命中率,那么直接在 decode worker 上本地计算 prefill 往往更高效。 Dynamo 的分离式设计考虑了这些不同场景,提供了一个灵活的框架,能够在各种条件下都实现出色的性能表现。
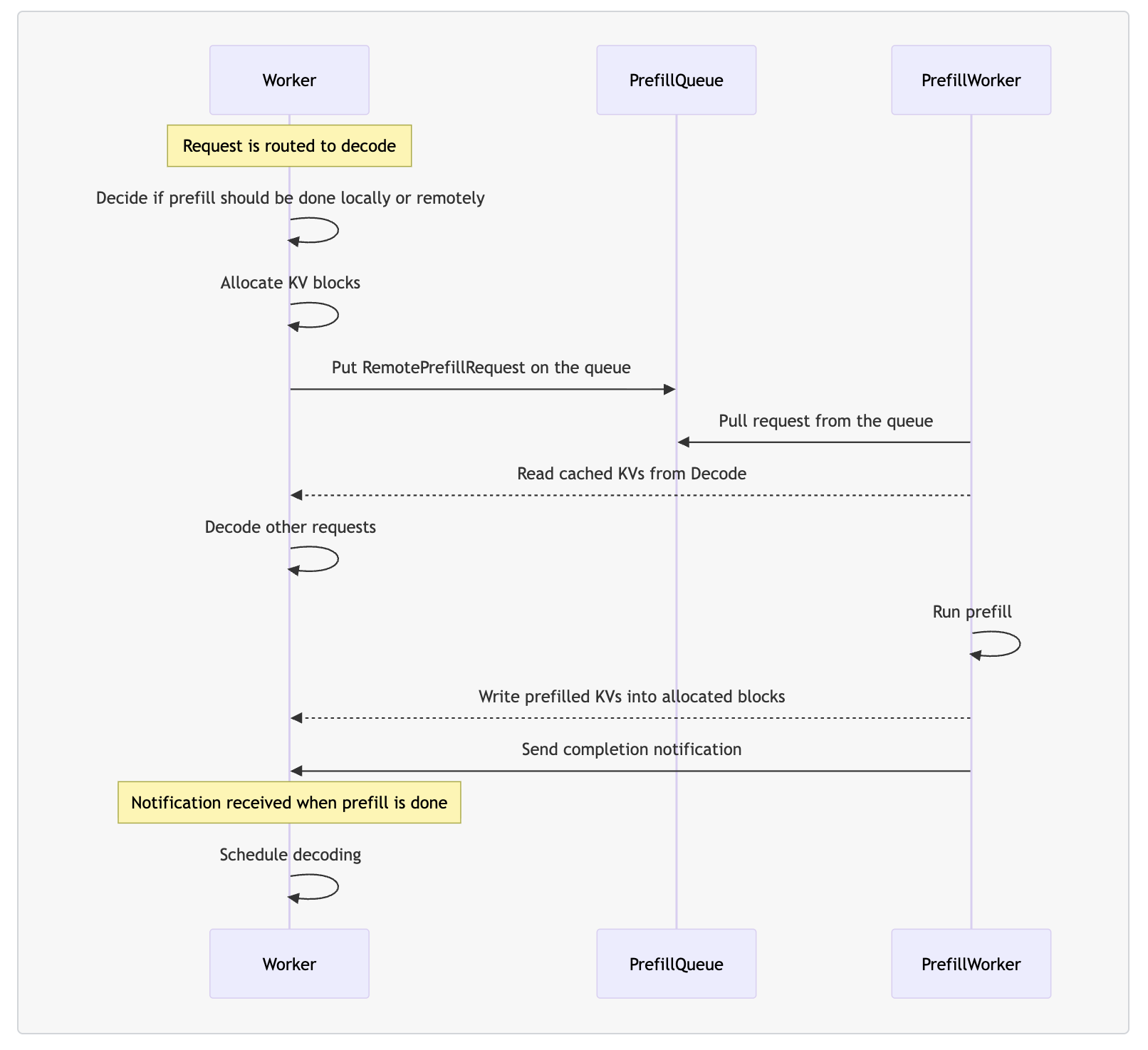
在 Dynamo 的 PD 分离架构中,有 4 个核心组件:
- (decode) worker:执行 prefill 和 decode 请求。
- prefill worker:只执行 prefill 请求。
- disaggregated router:决定 prefill 阶段是在本地还是远程执行。
- prefill queue:缓存并负载均衡远程 prefill 请求。
当 worker 收到请求时,首先会通过 disaggregated router 判断 prefill 应该在本地还是远程完成,并分配相应的 KV block。 如果选择远程 prefill,请求会被推送到 prefill queue。随后,prefill worker 从队列中取出请求,读取 worker 中 prefix cache 命中的 KV block,执行 prefill 计算,并将生成的 KV block 回写给 worker。最后,worker 会继续完成剩余的 decode 阶段。
接下来将演示如何通过 Dynamo 实现 PD 分离部署。首先打开一个新的终端并启动 decode worker 进程,将日志级别设置为 debug,以便我们进行观察。
export DYN_LOG=debug # Increase log verbosity to see disaggregation
CUDA_VISIBLE_DEVICES=0 python -m dynamo.vllm --model Qwen/Qwen3-0.6B打开另一个终端并启动 prefill worker 进程:
export DYN_LOG=debug # Increase log verbosity to see disaggregation
CUDA_VISIBLE_DEVICES=1 python -m dynamo.vllm --model Qwen/Qwen3-0.6B --is-prefill-worker打开第 3 个终端启动 frontend:
python -m dynamo.frontend --http-port 8000客户端发送推理请求:
curl -X POST http://localhost:8000/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "Qwen/Qwen3-0.6B",
"messages": [
{ "role": "user", "content": "Tell me a story about a cowardly cat" }
],
"stream": false,
"max_tokens": 1028
}'decode worker 从接收请求到完成处理的完整日志如下:
2025-09-07T07:05:21.915276Z DEBUG handlers._prefill_check_loop: Current Prefill Workers: 1
2025-09-07T07:05:26.920611Z DEBUG handlers._prefill_check_loop: Current Prefill Workers: 1
2025-09-07T07:05:29.017808Z DEBUG _core::engine: starting task to process python async generator stream request_id="02bfc326-5c79-40dc-bcf3-8f30251778ed"
2025-09-07T07:05:29.018227Z DEBUG handlers.generate: New Request ID: 0d2c9fea0c4944c6ba66ac7f9356a139
2025-09-07T07:05:29.018986Z DEBUG dynamo_runtime::pipeline::network::tcp::server: Registering new TcpStream on 10.63.146.171:44637
2025-09-07T07:05:29.076786Z DEBUG core._process_input_queue: EngineCore loop active.
2025-09-07T07:05:29.076928Z DEBUG nixl_connector.get_num_new_matched_tokens: NIXLConnector get_num_new_matched_tokens: num_computed_tokens=0, kv_transfer_params={'do_remote_prefill': True, 'do_remote_decode': False, 'remote_block_ids': [1, 2], 'remote_engine_id': '5f1cba5c-3231-4b30-9ea3-b393f5311e53', 'remote_host': '127.0.1.1', 'remote_port': 20420, 'tp_size': 1}
2025-09-07T07:05:29.077013Z DEBUG nixl_connector.update_state_after_alloc: NIXLConnector update_state_after_alloc: num_external_tokens=17, kv_transfer_params={'do_remote_prefill': True, 'do_remote_decode': False, 'remote_block_ids': [1, 2], 'remote_engine_id': '5f1cba5c-3231-4b30-9ea3-b393f5311e53', 'remote_host': '127.0.1.1', 'remote_port': 20420, 'tp_size': 1}
2025-09-07T07:05:29.077308Z DEBUG nixl_connector.start_load_kv: start_load_kv for request 0d2c9fea0c4944c6ba66ac7f9356a139 from remote engine 5f1cba5c-3231-4b30-9ea3-b393f5311e53. Num local_block_ids: 2. Num remote_block_ids: 2.
2025-09-07T07:05:29.078061Z DEBUG nixl_connector._nixl_handshake: Querying metadata on path: tcp://127.0.1.1:20420 at remote rank 0
2025-09-07T07:05:29.078361Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.078521Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.100638Z DEBUG nixl_connector._nixl_handshake: NIXL handshake: get metadata took: 0.022726254001099733
2025-09-07T07:05:29.661659Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.661936Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.665140Z DEBUG nixl_connector.add_remote_agent: Created 377496 blocks for dst engine 5f1cba5c-3231-4b30-9ea3-b393f5311e53 with remote rank 0 and local rank 0
2025-09-07T07:05:29.708358Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.708693Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.754379Z DEBUG nixl_connector._nixl_handshake: NIXL handshake: add agent took: 0.6485800469999958
2025-09-07T07:05:29.754653Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.760328Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.760571Z DEBUG nixl_connector._read_blocks_for_req: Remote agent 5f1cba5c-3231-4b30-9ea3-b393f5311e53 available, calling _read_blocks for req 0d2c9fea0c4944c6ba66ac7f9356a139
2025-09-07T07:05:29.761955Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.762335Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.763002Z DEBUG nixl_connector.get_finished: Rank 0, get_finished: 0 requests done sending and 1 requests done recving
2025-09-07T07:05:29.763202Z DEBUG scheduler._update_from_kv_xfer_finished: Finished recving KV transfer for request 0d2c9fea0c4944c6ba66ac7f9356a139
2025-09-07T07:05:29.763555Z DEBUG nixl_connector.update_state_after_alloc: NIXLConnector update_state_after_alloc: num_external_tokens=0, kv_transfer_params={'do_remote_prefill': False, 'do_remote_decode': False, 'remote_block_ids': [1, 2], 'remote_engine_id': '5f1cba5c-3231-4b30-9ea3-b393f5311e53', 'remote_host': '127.0.1.1', 'remote_port': 20420, 'tp_size': 1}
2025-09-07T07:05:31.921907Z DEBUG handlers._prefill_check_loop: Current Prefill Workers: 1
2025-09-07T07:05:36.773065Z DEBUG nixl_connector.request_finished: NIXLConnector request_finished, request_status=FINISHED_STOPPED, kv_transfer_params={'do_remote_prefill': False, 'do_remote_decode': False, 'remote_block_ids': [1, 2], 'remote_engine_id': '5f1cba5c-3231-4b30-9ea3-b393f5311e53', 'remote_host': '127.0.1.1', 'remote_port': 20420, 'tp_size': 1}
2025-09-07T07:05:36.773456Z DEBUG core._process_input_queue: EngineCore waiting for work.
2025-09-07T07:05:36.775360Z DEBUG _core::engine: finished processing python async generator stream request_id="02bfc326-5c79-40dc-bcf3-8f30251778ed"prefill worker 从接收请求到完成处理的完整日志如下:
2025-09-07T07:05:29.021115Z DEBUG _core::engine: starting task to process python async generator stream request_id="3536cede-1ea7-4868-936b-8e6bc58748b1"
2025-09-07T07:05:29.021290Z DEBUG handlers.generate: New Prefill Request ID: 0d2c9fea0c4944c6ba66ac7f9356a139
2025-09-07T07:05:29.023433Z DEBUG core._process_input_queue: EngineCore loop active.
2025-09-07T07:05:29.023733Z DEBUG nixl_connector.get_num_new_matched_tokens: NIXLConnector get_num_new_matched_tokens: num_computed_tokens=0, kv_transfer_params={'do_remote_decode': True}
2025-09-07T07:05:29.023825Z DEBUG nixl_connector.update_state_after_alloc: NIXLConnector update_state_after_alloc: num_external_tokens=0, kv_transfer_params={'do_remote_decode': True}
2025-09-07T07:05:29.069724Z DEBUG nixl_connector.request_finished: NIXLConnector request_finished, request_status=FINISHED_LENGTH_CAPPED, kv_transfer_params={'do_remote_decode': True}
2025-09-07T07:05:29.070486Z DEBUG core._process_input_queue: EngineCore waiting for work.
2025-09-07T07:05:29.071135Z DEBUG handlers.generate: kv transfer params: {'do_remote_prefill': True, 'do_remote_decode': False, 'remote_block_ids': [1, 2], 'remote_engine_id': '5f1cba5c-3231-4b30-9ea3-b393f5311e53', 'remote_host': '127.0.1.1', 'remote_port': 20420, 'tp_size': 1}
2025-09-07T07:05:29.071797Z DEBUG _core::engine: finished processing python async generator stream request_id="3536cede-1ea7-4868-936b-8e6bc58748b1"接下来,我们通过日志输出来详细解析 PD 分离架构处理请求的过程:
1.请求接收阶段
请求首先由 decode worker 接收并分配 Request ID,此时 disaggregated router 判定 prefill 阶段需要远程执行,请求会被推入 prefill queue,由 prefill worker 拉取后开始处理。日志中 prefill worker 打印的 Request ID 与 decode worker 保持一致,但时间戳会略晚于 decode worker。
# decode worker
2025-09-07T07:05:29.018227Z DEBUG handlers.generate: New Request ID: 0d2c9fea0c4944c6ba66ac7f9356a139
# prefill worker
2025-09-07T07:05:29.021290Z DEBUG handlers.generate: New Prefill Request ID: 0d2c9fea0c4944c6ba66ac7f9356a1392.prefill worker 处理请求
# prefill worker 日志
# 以下代码注释来自 vLLM v0.10.1.1 和 Dynamo 0.4.1
# vLLM engine 变为活跃状态,开始处理请求
# vllm: vllm/v1/engine/core.py: 753 行
2025-09-07T07:05:29.023433Z DEBUG core._process_input_queue: EngineCore loop active.
# vllm: vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py: 276 行
# 在 prefill worker 的日志中,num_computed_tokens=0 表明这个请求还没有计算过任何 token,需要从头开始进行 prefill 计算
# kv_transfer_params={'do_remote_decode': True} 是从 decode worker 接收到的 KV transfer 参数,表明请求来自远程 decode worker
2025-09-07T07:05:29.023733Z DEBUG nixl_connector.get_num_new_matched_tokens: NIXLConnector get_num_new_matched_tokens: num_computed_tokens=0, kv_transfer_params={'do_remote_decode': True}
# vllm: vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py: 295 行
# 在分配完 block 后调用,当 NIXL 不直接支持该 Accelerator 时(kv_buffer_device == "cpu"),prefill 计算的 block 需要在 KV transfer 之前先存储到 host memory。在我们的例子中使用的是 GPU,不需要将 KV cache 先保存到 host memory,可以直接从 GPU 内存进行传输。
# num_external_tokens=0 表明没有外部 token 需要加载
2025-09-07T07:05:29.023825Z DEBUG nixl_connector.update_state_after_alloc: NIXLConnector update_state_after_alloc: num_external_tokens=0, kv_transfer_params={'do_remote_decode': True}
# vllm: vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py: 383 行
# 由于 prefill worker 的 max_tokens=1,当生成一个 token 后就达到长度限制,状态被设置为 FINISHED_LENGTH_CAPPED
# 当请求处理完成后,scheduler 会调用 request_finished() 方法,由于 do_remote_decode=True 且状态为 FINISHED_LENGTH_CAPPED,
# 决定延迟释放 KV block,等待 decode worker 后续通过 NIXL 连接异步拉取 KV cache
2025-09-07T07:05:29.069724Z DEBUG nixl_connector.request_finished: NIXLConnector request_finished, request_status=FINISHED_LENGTH_CAPPED, kv_transfer_params={'do_remote_decode': True}
# vllm: vllm/v1/engine/core.py: 747 行
# vLLM engine 回到空闲状态,等待新的请求
2025-09-07T07:05:29.070486Z DEBUG core._process_input_queue: EngineCore waiting for work.
# dynamo: components/backends/vllm/src/dynamo/vllm/handlers.py: 184 行
# prefill worker 返回给 decode worker 的 KV transfer 参数,告诉 decode 去哪里拉取已经计算好的 prefill 阶段的 KV cache,以便继续生成 decode 阶段的 token
2025-09-07T07:05:29.071135Z DEBUG handlers.generate: kv transfer params: {'do_remote_prefill': True, 'do_remote_decode': False, 'remote_block_ids': [1, 2], 'remote_engine_id': '5f1cba5c-3231-4b30-9ea3-b393f5311e53', 'remote_host': '127.0.1.1', 'remote_port': 20420, 'tp_size': 1}3.decode worker 处理请求
# decode worker 日志
# 以下代码注释来自 vLLM v0.10.1.1 和 Dynamo 0.4.1
# vLLM engine 变为活跃状态,开始处理请求
# vllm: vllm/v1/engine/core.py: 753 行
2025-09-07T07:05:29.076786Z DEBUG core._process_input_queue: EngineCore loop active.
# vllm: vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py: 276 行
# 在 decode worker 中,num_computed_tokens=0 表明 decode worker 尚未对这个请求进行任何计算
# 由于 KV transfer 参数中 do_remote_prefill=True,decode worker 会计算出可以从外部 KV cache 加载的 token 数量(len(request.prompt_token_ids) - num_computed_tokens)
# 并将从 prefill worker 的 remote_block_ids=[1,2] 拉取对应的 KV cache
2025-09-07T07:05:29.076928Z DEBUG nixl_connector.get_num_new_matched_tokens: NIXLConnector get_num_new_matched_tokens: num_computed_tokens=0, kv_transfer_params={'do_remote_prefill': True, 'do_remote_decode': False, 'remote_block_ids': [1, 2], 'remote_engine_id': '5f1cba5c-3231-4b30-9ea3-b393f5311e53', 'remote_host': '127.0.1.1', 'remote_port': 20420, 'tp_size': 1}
# vllm: vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py: 295 行
# num_external_tokens=17 表明 decode worker 已为 17 个外部 token 分配了 KV cache 内存空间,并将该请求注册到 _reqs_need_recv 队列中,
# 等待后续调度循环中通过异步拉取 remote_block_ids=[1,2] 对应的 KV cache
2025-09-07T07:05:29.077013Z DEBUG nixl_connector.update_state_after_alloc: NIXLConnector update_state_after_alloc: num_external_tokens=17, kv_transfer_params={'do_remote_prefill': True, 'do_remote_decode': False, 'remote_block_ids': [1, 2], 'remote_engine_id': '5f1cba5c-3231-4b30-9ea3-b393f5311e53', 'remote_host': '127.0.1.1', 'remote_port': 20420, 'tp_size': 1}
# vllm: vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py: 1118 行
# decode worker 开始从 prefill worker 拉取对应的 KV cache
2025-09-07T07:05:29.077308Z DEBUG nixl_connector.start_load_kv: start_load_kv for request 0d2c9fea0c4944c6ba66ac7f9356a139 from remote engine 5f1cba5c-3231-4b30-9ea3-b393f5311e53. Num local_block_ids: 2. Num remote_block_ids: 2.
# vllm: vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py: 607 行
# decode worker 查询连接元数据,开始与 prefill worker 建立 NIXL 连接
2025-09-07T07:05:29.078061Z DEBUG nixl_connector._nixl_handshake: Querying metadata on path: tcp://127.0.1.1:20420 at remote rank 0
# vllm: vllm/v1/core/sched/scheduler.py: 347 行
# decode worker 等待 KV cache 传输完成,scheduler 会持续检查 KV cache 传输状态,直到完成后才会调度该请求继续执行
2025-09-07T07:05:29.078361Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.078521Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
# vllm: vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py: 617 行
# NIXL 握手过程中,获取元数据耗时约 22.7 毫秒
2025-09-07T07:05:29.100638Z DEBUG nixl_connector._nixl_handshake: NIXL handshake: get metadata took: 0.022726254001099733
# decode worker 等待 KV cache 传输完成
2025-09-07T07:05:29.661659Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.661936Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
# vllm: vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py: 978 行
# 添加远程 NIXL agent 并准备用于从远程读取 KV cache block 的描述符
2025-09-07T07:05:29.665140Z DEBUG nixl_connector.add_remote_agent: Created 377496 blocks for dst engine 5f1cba5c-3231-4b30-9ea3-b393f5311e53 with remote rank 0 and local rank 0
# decode worker 等待 KV cache 传输完成
2025-09-07T07:05:29.708358Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.708693Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
# vllm: vllm: vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py: 630 行
# 添加远程 NIXL agent 耗时约 648 毫秒
2025-09-07T07:05:29.754379Z DEBUG nixl_connector._nixl_handshake: NIXL handshake: add agent took: 0.6485800469999958
# decode worker 等待 KV cache 传输完成
2025-09-07T07:05:29.754653Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.760328Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
# vllm: vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py: 1144 行
# 远程 NIXL agent 已准备就绪,开始调用 _read_blocks() 方法从远程读取 KV cache
2025-09-07T07:05:29.760571Z DEBUG nixl_connector._read_blocks_for_req: Remote agent 5f1cba5c-3231-4b30-9ea3-b393f5311e53 available, calling _read_blocks for req 0d2c9fea0c4944c6ba66ac7f9356a139
# decode worker 等待 KV cache 传输完成
2025-09-07T07:05:29.761955Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
2025-09-07T07:05:29.762335Z DEBUG scheduler.schedule: 0d2c9fea0c4944c6ba66ac7f9356a139 is still in WAITING_FOR_REMOTE_KVS state.
# vllm: vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py: 1030 行
# 检查 KV cache 传输完成状态,发现 1 个请求的 KV cache 接收已完成
# 这个状态信息通过 _update_from_kv_xfer_finished() 返回给 scheduler,scheduler 将在下次调度循环中通过 _update_waiting_for_remote_kv() 将相应请求从 WAITING_FOR_REMOTE_KVS 状态转为 WAITING 可调度状态
2025-09-07T07:05:29.763002Z DEBUG nixl_connector.get_finished: Rank 0, get_finished: 0 requests done sending and 1 requests done recving
# vllm: vllm/v1/core/sched/scheduler.py: 1263 行
# scheduler 确认 KV cache 传输完成,将请求标记为可调度状态,准备在下次调度循环中继续处理该请求
2025-09-07T07:05:29.763202Z DEBUG scheduler._update_from_kv_xfer_finished: Finished recving KV transfer for request 0d2c9fea0c4944c6ba66ac7f9356a139
# vllm: vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py: 295 行
# 此时 KV cache 已经传输完成,update_state_after_alloc() 方法会直接返回,不会执行任何特殊的逻辑
2025-09-07T07:05:29.763555Z DEBUG nixl_connector.update_state_after_alloc: NIXLConnector update_state_after_alloc: num_external_tokens=0, kv_transfer_params={'do_remote_prefill': False, 'do_remote_decode': False, 'remote_block_ids': [1, 2], 'remote_engine_id': '5f1cba5c-3231-4b30-9ea3-b393f5311e53', 'remote_host': '127.0.1.1', 'remote_port': 20420, 'tp_size': 1}
# vllm: vllm/distributed/kv_transfer/kv_connector/v1/nixl_connector.py: 383 行
# decode worker 完成 token 生成任务,整个 PD 分离流程结束,KV block 可以正常释放
2025-09-07T07:05:36.773065Z DEBUG nixl_connector.request_finished: NIXLConnector request_finished, request_status=FINISHED_STOPPED, kv_transfer_params={'do_remote_prefill': False, 'do_remote_decode': False, 'remote_block_ids': [1, 2], 'remote_engine_id': '5f1cba5c-3231-4b30-9ea3-b393f5311e53', 'remote_host': '127.0.1.1', 'remote_port': 20420, 'tp_size': 1}
# vllm: vllm/v1/engine/core.py: 747 行
# vLLM engine 回到空闲状态,等待新的请求
2025-09-07T07:05:36.773456Z DEBUG core._process_input_queue: EngineCore waiting for work.3.3 在 Kubernetes 上部署 Dynamo
前面我们介绍了本地使用 Dynamo 的方法,而在生产环境中要发挥其分布式推理能力则需要在 Kubernetes 上部署。Dynamo 提供了 Dynamo Operator,用户可通过 DynamoGraphDeployment CRD 编排 frontend、prefill worker 和 decode worker,以声明式、云原生的方式实现高效的分布式推理。
接下来将展示如何在 Kubernetes 上部署 Dynamo,并且运行快速开始和 PD 分离示例。
首先,执行以下命令安装 kubectl 和 helm:
snap install kubectl --classic
snap install helm --classic本文将会使用 Minikube 来安装一个单节点的 Kubernetes 集群。执行以下命令安装 Minikube:
curl -LO https://github.com/kubernetes/minikube/releases/latest/download/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube && rm minikube-linux-amd64启动支持 GPU 的 Minikube 集群,并且安装 Dynamo 所需的 addon。
minikube start --driver docker --container-runtime docker --gpus all --memory=16000mb --cpus=8 --force
# Enable required addons
minikube addons enable istio-provisioner
minikube addons enable istio
minikube addons enable storage-provisioner-rancher确认所有 Pod 都已经成功运行。
> kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
istio-operator istio-operator-b88fb5f65-pldzx 1/1 Running 0 47s
istio-system istio-ingressgateway-64887df48f-sfqvr 1/1 Running 0 26s
istio-system istiod-65c5bcc875-v27jd 1/1 Running 0 32s
kube-system coredns-674b8bbfcf-lqz8h 1/1 Running 0 13m
kube-system etcd-minikube 1/1 Running 0 13m
kube-system kube-apiserver-minikube 1/1 Running 0 13m
kube-system kube-controller-manager-minikube 1/1 Running 0 13m
kube-system kube-proxy-pnlmw 1/1 Running 0 13m
kube-system kube-scheduler-minikube 1/1 Running 0 13m
kube-system nvidia-device-plugin-daemonset-wxtg8 1/1 Running 0 13m
kube-system storage-provisioner 1/1 Running 0 13m
local-path-storage local-path-provisioner-76f89f99b5-748sw 1/1 Running 0 37s安装 Dynamo Kubernetes Platform:
# 1. Set environment
export NAMESPACE=dynamo-kubernetes
export RELEASE_VERSION=0.4.1 # any version of Dynamo 0.3.2+
# 2. Install CRDs
helm fetch https://helm.ngc.nvidia.com/nvidia/ai-dynamo/charts/dynamo-crds-${RELEASE_VERSION}.tgz
helm install dynamo-crds dynamo-crds-${RELEASE_VERSION}.tgz --namespace default
# 3. Install Platform
kubectl create namespace ${NAMESPACE}
helm fetch https://helm.ngc.nvidia.com/nvidia/ai-dynamo/charts/dynamo-platform-${RELEASE_VERSION}.tgz
helm install dynamo-platform dynamo-platform-${RELEASE_VERSION}.tgz --namespace ${NAMESPACE} --set dynamo-operator.namespaceRestriction.enabled=false确认 Dynamo 的 CRD 已成功安装,并且 Dynamo 相关组件已正常运行。
> kubectl get crd | grep dynamo
dynamocomponentdeployments.nvidia.com 2025-08-31T08:50:40Z
dynamographdeployments.nvidia.com 2025-08-31T08:50:40Z
> kubectl get pods -n ${NAMESPACE}
NAME READY STATUS RESTARTS AGE
dynamo-platform-dynamo-operator-controller-manager-6c7fc65kcqpx 2/2 Running 0 34s
dynamo-platform-etcd-0 1/1 Running 0 34s
dynamo-platform-nats-0 2/2 Running 0 34s
dynamo-platform-nats-box-5dbf45c748-zk7xd 1/1 Running 0 34s接下来通过 DynamoGraphDeployment 定义一个最简单的 vLLM 推理服务,其中包含一个 Frontend 和一个 VllmDecodeWorker。
apiVersion: nvidia.com/v1alpha1
kind: DynamoGraphDeployment
metadata:
name: vllm-agg
spec:
services:
Frontend:
dynamoNamespace: vllm-agg
componentType: frontend
replicas: 1
extraPodSpec:
mainContainer:
image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.4.1
VllmDecodeWorker:
dynamoNamespace: vllm-agg
componentType: worker
replicas: 1
resources:
limits:
gpu: "1"
extraPodSpec:
mainContainer:
image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.4.1
workingDir: /workspace/components/backends/vllm
command:
- /bin/sh
- -c
args:
- python3 -m dynamo.vllm --model Qwen/Qwen3-0.6B部署完成后,确认 vllm-agg 的 Pod 和 Service 已经成功创建。
root@a4u8g-0061:/localhome/local-sevenc# kubectl get pod,svc
NAME READY STATUS RESTARTS AGE
pod/vllm-agg-frontend-bbf7987c7-6tkqm 1/1 Running 0 2m43s
pod/vllm-agg-vllmdecodeworker-5b6c7c5877-5l6g8 1/1 Running 0 2m42s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/vllm-agg-frontend ClusterIP 10.98.218.92 <none> 8000/TCP 2m43s使用端口转发将本地 8000 端口映射到 Frontend Service,以便进行测试。
kubectl port-forward svc/vllm-agg-frontend 8000:8000向 Frontend Service 发送 HTTP 请求以执行推理。
curl -X POST http://localhost:8000/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "Qwen/Qwen3-0.6B",
"messages": [
{ "role": "user", "content": "Tell me a story about a cowardly cat" }
],
"stream": false,
"max_tokens": 50
}'
# 响应
{"id":"chatcmpl-62d76a88-6a0c-41d1-af22-2f3582e29523","choices":[{"index":0,"message":{"content":"<think>\nOkay, the user wants a story about a cowardly cat. Let me start by thinking about how to approach this. First, I need to create a relatable character. Maybe a cat named something like Whiskers. Whisk","role":"assistant","reasoning_content":null},"finish_reason":"stop"}],"created":1756640102,"model":"Qwen/Qwen3-0.6B","object":"chat.completion","usage":{"prompt_tokens":17,"completion_tokens":49,"total_tokens":66}}通过 DynamoGraphDeployment 部署一个基于 PD 分离架构的 vLLM 推理服务也很简单,只需在配置文件中声明 Frontend、VllmDecodeWorker 和 VllmPrefillWorker 三个组件即可。dynamoNamespace 是 Dynamo 分布式运行时的逻辑隔离单元,而非 Kubernetes 的 namespace;同一 dynamoNamespace 内的组件可以相互发现并进行通信。
apiVersion: nvidia.com/v1alpha1
kind: DynamoGraphDeployment
metadata:
name: vllm-disagg
spec:
services:
Frontend:
dynamoNamespace: vllm-disagg
componentType: frontend
replicas: 1
extraPodSpec:
mainContainer:
image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.4.1
VllmDecodeWorker:
dynamoNamespace: vllm-disagg
componentType: worker
replicas: 1
resources:
limits:
gpu: "1"
extraPodSpec:
mainContainer:
image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.4.1
workingDir: /workspace/components/backends/vllm
command:
- /bin/sh
- -c
args:
- "python3 -m dynamo.vllm --model Qwen/Qwen3-0.6B"
VllmPrefillWorker:
dynamoNamespace: vllm-disagg
componentType: worker
replicas: 1
resources:
limits:
gpu: "1"
extraPodSpec:
mainContainer:
image: nvcr.io/nvidia/ai-dynamo/vllm-runtime:0.4.1
workingDir: /workspace/components/backends/vllm
command:
- /bin/sh
- -c
args:
- "python3 -m dynamo.vllm --model Qwen/Qwen3-0.6B --is-prefill-worker"部署完成后,可以看到分别创建了 Frontend、VllmDecodeWorker 和 VllmPrefillWorker 的 Pod。
root@a4u8g-0061:/localhome/local-sevenc# kubectl get pod,svc
NAME READY STATUS RESTARTS AGE
pod/vllm-disagg-frontend-76c47ddfbf-v592k 1/1 Running 0 17m
pod/vllm-disagg-vllmdecodeworker-7db6c8c857-qdmw9 1/1 Running 0 17m
pod/vllm-disagg-vllmprefillworker-79cf89956c-6scz2 1/1 Running 0 17m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/vllm-disagg-frontend ClusterIP 10.102.108.42 <none> 8000/TCP 17m同理,使用端口转发访问 PD 分离架构的 Frontend Service。
kubectl port-forward svc/vllm-disagg-frontend 8000:8000客户端发送推理请求进行访问。
curl -X POST http://localhost:8000/v1/chat/completions \
-H 'Content-Type: application/json' \
-d '{
"model": "Qwen/Qwen3-0.6B",
"messages": [
{ "role": "user", "content": "Tell me a story about a cowardly cat" }
],
"stream": false,
"max_tokens": 50
}'
# PD 分离架构响应
{"id":"chatcmpl-d79fbfe0-e8d1-4752-a47c-92c76ba8ef94","choices":[{"index":0,"message":{"content":"<think>\nOkay, the user wants a story about a cowardly cat. Let me start by brainstorming some ideas. A cat that's not brave in a traditional sense. Maybe a cat who hides or avoids danger. I need to make sure","role":"assistant","reasoning_content":null},"finish_reason":"stop"}],"created":1756641275,"model":"Qwen/Qwen3-0.6B","object":"chat.completion","usage":{"prompt_tokens":17,"completion_tokens":49,"total_tokens":66}}4 总结
本文详细介绍了 NVIDIA Dynamo 分布式推理框架的核心概念与实践。文章不仅演示了 Dynamo 在最简单部署模式下的运行方式,还重点讲解了 PD 分离模式,通过将 prefill 与 decode 阶段拆分到不同 GPU 节点,并结合高效数据传输机制,实现了推理吞吐量与效率的显著提升。同时,文章还展示了在 Kubernetes 环境下的部署方法,通过云原生能力轻松实现生产级的分布式推理。
5 参考资料
- Dynamo Examples:https://github.com/ai-dynamo/dynamo/tree/main/examples
- vLLM Kubernetes Deployment Configurations:https://github.com/ai-dynamo/dynamo/blob/main/components/backends/vllm/deploy/README.md
- Installing the NVIDIA Container Toolkit:https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
- TKE 上使用 NVIDIA Dynamo 部署 PD 分离的大模型:https://cloud.tencent.com/developer/article/2515122
- NVIDIA Dynamo, A Low-Latency Distributed Inference Framework for Scaling Reasoning AI Models:https://developer.nvidia.com/blog/introducing-nvidia-dynamo-a-low-latency-distributed-inference-framework-for-scaling-reasoning-ai-models/
- NVDIA Dynamo推理框架技术解析:https://zhuanlan.zhihu.com/p/1886300967491830777
- 代码演示 | 使用 NVIDIA Dynamo 进行 P/D 分离服务:https://www.bilibili.com/video/BV1ow8wz9Ece
欢迎关注
