使用 seekdb + PowerMem 构建多模态智能记忆系统 MemBox
在与 AI 应用交互时,你有没有经历过这样的场景:每次新会话都要重新介绍自己是谁、在做什么项目,刚才聊过的偏好转眼就被忘得一干二净?这是因为大多数大语言模型本质上是无状态的——每一次对话都是从零开始,上下文窗口有限且无法持久化。
如果能让 AI "记住"用户——不仅记住当前对话,还能记住历史交互、个人偏好和用户画像——它就能成为真正有"成长性"的智能助手。本文将介绍如何使用 OceanBase 推出的 SeekDB(AI 原生混合搜索数据库)和 PowerMem(智能记忆管理库)构建一个多模态智能记忆系统 MemBox,实现用户记忆持久化、语义检索和个性化回复,让 AI 拥有跨会话的"长期记忆"。
1. SeekDB 介绍
seekdb 是 OceanBase 推出的 AI 原生混合搜索数据库,在一个数据库中融合向量、文本、结构化与半结构化数据能力,并通过内置 AI Functions 支持多模混合搜索与智能推理。
SeekDB 的核心特性:
- 灵活部署:支持嵌入式和服务器两种部署模式。嵌入式模式下可将 seekdb 直接集成进 Python 应用,便于进行个人开发。
- 混合搜索:向量、全文与标量过滤在一次查询中完成,支持粗排 + 精排的多阶段搜索链路。
- 多模数据与索引:支持向量、文本、JSON、GIS 等多模数据,提供 HNSW/IVF 向量索引、BM25 全文索引等。
- AI 内置:在数据库内完成向量嵌入、推理、提示词管理与重排,支持 document-in/data-out 的完整 RAG 流程。
- SQL 原生:源于成熟的 OceanBase 引擎,支持实时写入、实时可查,ACID 事务保证,兼容 MySQL 生态。
- 统一应用接口:适配 LangChain、LlamaIndex、Dify 等近 30 种 AI 框架,提供 MCP Server。

2. PowerMem 介绍
PowerMem 是一个智能记忆管理库。在 AI 应用开发中,如何让大语言模型持久化地"记住"历史对话、用户偏好和上下文信息是一个核心挑战。PowerMem 融合向量检索、全文检索和图数据库的混合存储架构,为 AI 应用构建了强大的记忆基础设施。
PowerMem 的核心特性:
- 轻量级接入:提供简洁的 Python SDK,还支持 MCP Server 和 HTTP API Server 接入。
- 智能记忆提取:通过 LLM 自动从对话中提取关键事实,智能检测重复、更新冲突信息并合并相关记忆。
- 用户画像:自动构建和更新用户画像,让 AI 更好地理解每个用户。
- 多用户/多智能体隔离:为每个用户或智能体提供独立的记忆空间,支持跨智能体协作。
- 多模态支持:支持文本、图像、语音等多模态内容的记忆和检索。
- 混合检索:融合向量检索、全文搜索和图检索的多路召回能力。
3. 项目效果预览
本文将带你使用 seekdb + PowerMem 从零构建一个多模态智能记忆系统 MemBox。MemBox 可以自动从对话中提取关键信息、构建用户画像、理解图片内容,并在后续对话中智能检索相关记忆,提供个性化回答。先来看看最终效果:
4. 准备工作
4.1 环境要求
4.2 获取 API Key
本项目使用阿里云通义千问模型,需要获取阿里云百炼的 API Key:
- 访问阿里云百炼控制台。
- 开通服务并创建 API Key。
4.3 启动 SeekDB
使用 Docker 快速启动 seekdb:
docker run -d \
--name seekdb \
-p 2881:2881 \
-v seekdb_data:/var/lib/oceanbase \
oceanbase/seekdb:1.0.1.0-1000003920251226194.4 环境变量设置
本项目需要配置环境变量,可参考 .env.example 文件,将其复制为 .env 并填入相应值。其中只需配置 DASHSCOPE_API_KEY 用于调用千问大模型,其他变量可保持默认。
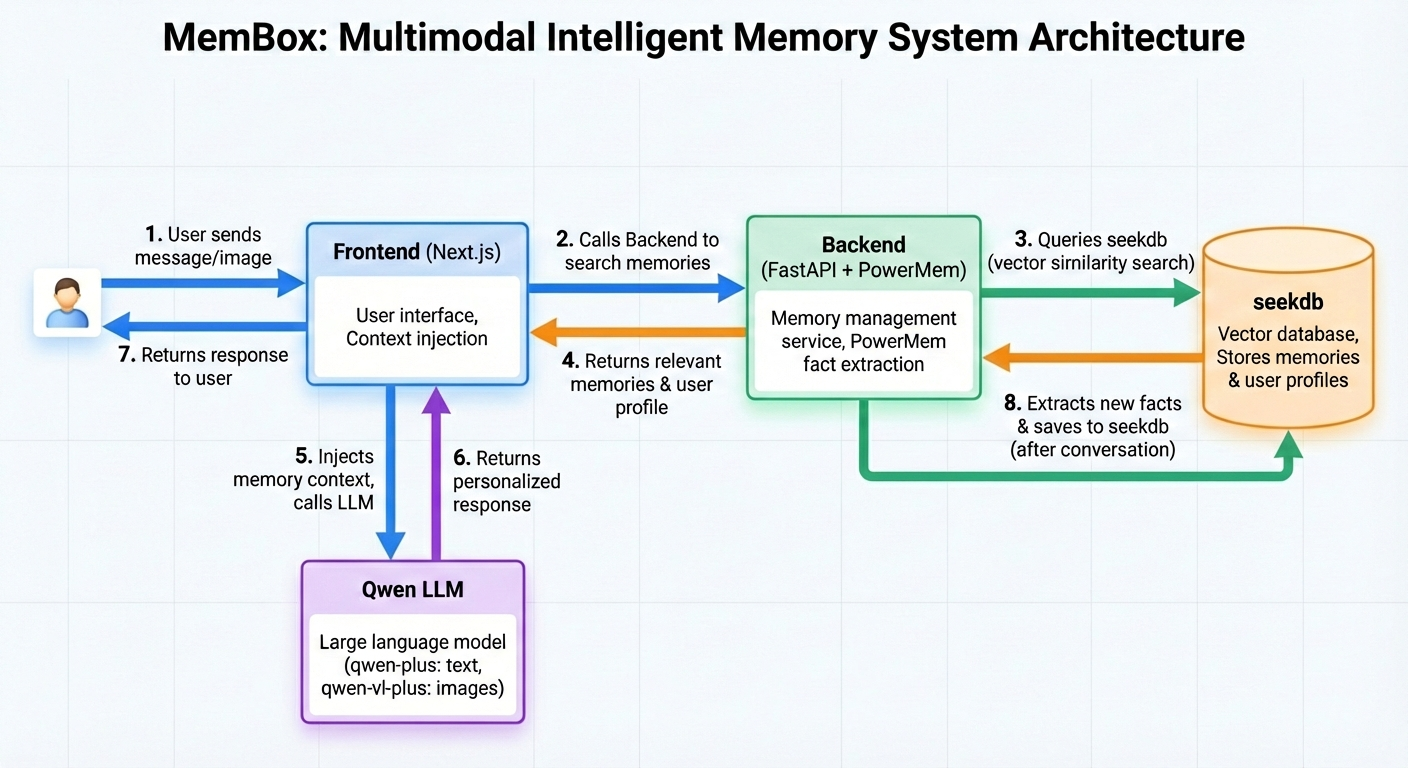
5. 整体架构
当用户与 MemBox 对话时,完整的请求流程如下:
- 用户输入:用户在前端发送消息(可包含文字和图片)。
- 记忆检索:前端调用后端搜索相关记忆。
- 向量搜索:后端使用 PowerMem 将查询通过 text-embedding-v4 模型转换为向量,在 seekdb 中进行相似度搜索。
- 返回结果:seekdb 返回相关记忆和用户画像。
- 上下文注入:前端将记忆上下文注入 LLM 的 System Prompt。
- 生成回答:前端调用 qwen-plus 模型生成回答,如有图片则使用多模态模型 qwen-vl-plus 模型理解图片内容。
- 返回响应:LLM 将回答返回给用户。
- 记忆存储:对话结束后,PowerMem 提取新的事实信息,通过 text-embedding-v4 向量化后存入 seekdb。
本文的完整代码可以在 Github 上找到:https://github.com/cr7258/membox
6. 搭建后端(FastAPI + PowerMem)
6.1 配置 PowerMem
PowerMem 支持两种配置方式:
- 环境变量(
.env文件):适合大多数场景,PowerMem 会自动加载。 - JSON/ Python 字典配置:适合在代码中灵活管理配置的场景。
本项目使用 JSON/Python 字典配置方式,config.py 配置如下:
config = {
# LLM 配置 - 用于智能记忆提取和用户画像
"llm": {
"provider": "qwen",
"config": {
"model": os.getenv("LLM_MODEL", "qwen-plus"),
"api_key": os.getenv("DASHSCOPE_API_KEY"),
}
},
# Embedding 配置 - 用于向量化
"embedder": {
"provider": "qwen",
"config": {
"model": os.getenv("EMBEDDING_MODEL", "text-embedding-v4"),
"embedding_dims": int(os.getenv("EMBEDDING_DIMS", "1536")),
"api_key": os.getenv("DASHSCOPE_API_KEY"),
}
},
# 向量存储配置 - SeekDB (OceanBase)
"vector_store": {
"provider": "oceanbase",
"config": {
"collection_name": "memories",
"embedding_model_dims": int(os.getenv("EMBEDDING_DIMS", "1536")),
"host": os.getenv("OCEANBASE_HOST", "127.0.0.1"),
"port": int(os.getenv("OCEANBASE_PORT", "2881")),
"user": os.getenv("OCEANBASE_USER", "root@sys"),
"password": os.getenv("OCEANBASE_PASSWORD", ""),
"db_name": os.getenv("OCEANBASE_DATABASE", "membox"),
}
},
}6.2 记忆管理
memory_manager.py 封装了 PowerMem 的核心操作,主要包含两个方法:
- add_memory:从对话中提取并保存记忆。通过
infer=True启用智能提取,PowerMem 会自动从对话中提取事实信息、去重、更新冲突内容并整合相关记忆。通过user_id实现用户隔离,每个用户的记忆独立存储。 - search_memory:搜索与查询相关的记忆。通过
add_profile=True在返回结果中包含用户画像,帮助 LLM 生成更个性化的回复。搜索时会根据user_id过滤,只返回当前用户的记忆。
from powermem import UserMemory
from .config import config
class MemoryManager:
def __init__(self):
self.memory = UserMemory(config=config)
def add_memory(self, messages: list, user_id: str) -> dict:
"""从对话中提取并保存记忆"""
result = self.memory.add(
messages=messages,
user_id=user_id,
infer=True # 启用智能提取
)
return result
def search_memory(self, query: str, user_id: str, limit: int = 5) -> dict:
"""搜索相关记忆"""
results = self.memory.search(
query=query,
user_id=user_id,
limit=limit,
add_profile=True # 同时返回用户画像
)
return results6.3 实现 API 路由
routes/memory.py 提供记忆相关的 RESTful API,供前端调用:
- POST /api/memory/add:前端在对话结束后调用,将用户和 AI 的对话内容发送到后端进行记忆提取和存储。
- POST /api/memory/search:前端在用户发送新消息前调用,搜索相关记忆和用户画像,注入到 LLM 的系统提示词中。
from fastapi import APIRouter, HTTPException
from pydantic import BaseModel
from ..memory_manager import get_memory_manager
router = APIRouter()
class AddMemoryRequest(BaseModel):
messages: list[dict[str, str]]
user_id: str
class SearchMemoryRequest(BaseModel):
query: str
user_id: str
limit: int = 5
@router.post("/add")
async def add_memory(request: AddMemoryRequest):
"""添加记忆"""
mm = get_memory_manager()
result = mm.add_memory(
messages=request.messages,
user_id=request.user_id
)
return {"success": True, "result": result}
@router.post("/search")
async def search_memory(request: SearchMemoryRequest):
"""搜索记忆"""
mm = get_memory_manager()
results = mm.search_memory(
query=request.query,
user_id=request.user_id,
limit=request.limit
)
return results7. 添加多模态支持
MemBox 支持图片理解功能,用户可以上传图片并提问。整体流程如下:
- 图片上传:用户选择图片,前端上传到后端获取 URL,用于在聊天历史记录中显示图片预览。
- 图片理解:前端将图片 URL 传给 Vercel AI SDK,SDK 自动下载图片并转成 base64 发送给 qwen-vl-plus。
- 记忆保存:LLM 的回复(包含对图片的理解描述)作为文本保存到 PowerMem 中。
这样做的好处是后端只需提供简单的图片存储服务,多模态理解由 Vercel AI SDK 和前端统一处理。
注意:PowerMem 也原生支持多模态记忆,可以在配置中设置
enable_vision: True和vision_details: "auto"并配置相应的多模态模型(如 qwen-vl-plus),让后端直接理解图片内容并存储为记忆。具体参考 PowerMem 多模态示例。
7.1 图片上传 API
后端 routes/upload.py 提供图片上传接口,将图片保存到本地并返回访问 URL:
@router.post("/images")
async def upload_images(
files: List[UploadFile] = File(...),
user_id: str = Form(...)
):
try:
uploaded_urls = []
uploaded_filenames = []
for file in files:
# Check file type
ext = get_file_extension(file.filename)
if ext not in ALLOWED_EXTENSIONS:
raise HTTPException(...)
# Generate filename and save
filename = generate_filename(file.filename)
filepath = os.path.join(UPLOAD_DIR, filename)
with open(filepath, "wb") as f:
content = await file.read()
f.write(content)
# Generate image URL
base_url = os.getenv("BASE_URL", "http://localhost:8000")
image_url = f"{base_url}/uploads/{filename}"
uploaded_urls.append(image_url)
uploaded_filenames.append(filename)
return {
"success": True,
"count": len(uploaded_urls),
"filenames": uploaded_filenames,
"urls": uploaded_urls
}
except Exception as e:
# ... error handling
raise HTTPException(status_code=500, detail=str(e))7.2 启动后端
可以使用以下命令启动后端服务:
cd backend
uv run membox8. 搭建前端(Next.js + Vercel AI SDK)
前端基于 Next.js 构建,主要使用以下技术栈:
- Vercel AI SDK
- AI Elements
- ui-ux-pro-max-skill
8.1 Vercel AI SDK
将大语言模型(LLM)集成到应用中是一件复杂的事情,而且高度依赖于你使用的模型提供商。Vercel AI SDK 标准化了跨不同提供商的 AI 模型集成方式,让开发者可以专注于构建优秀的 AI 应用,而不是在技术细节上浪费时间。
AI SDK 包含两个主要模块:
- AI SDK Core:提供统一的 API,用于生成文本、结构化对象、工具调用以及使用 LLM 构建 Agent。
- AI SDK UI:提供一组与框架无关的 hooks,用于快速构建聊天界面和生成式 UI。
8.2 AI Elements
AI Elements 是基于 shadcn/ui 构建的组件库,帮助开发者更快地构建 AI 原生应用。它提供了预构建的组件,如对话框、消息气泡等,可以通过 CLI 命令快速安装:
8.3 UI/UX 设计
本项目使用 ui-ux-pro-max-skill 辅助设计页面风格和样式。这是一个 AI Skill,能够为多平台提供专业的 UI/UX 设计智能,自动生成设计系统并推荐最佳的颜色、字体和间距方案。
8.4 聊天状态管理
app/page.tsx 是前端的核心页面,使用多个 hooks 管理状态:
- useUser:管理用户登录、切换、登出。
- useChatSessions:管理聊天会话的创建、切换、删除,按用户隔离。
- useChat:Vercel AI SDK 提供的 hook,管理消息发送和接收。
import { useChat } from "@ai-sdk/react";
import { useChatSessions } from "@/hooks/use-chat-sessions";
import { useUser } from "@/hooks/use-user";
export default function Home() {
const [pendingImages, setPendingImages] = useState<string[]>([]);
// 用户管理
const { currentUser, login, switchUser, logout } = useUser();
// 聊天会话管理(按用户过滤)
const {
sessions,
currentSession,
currentSessionId,
createSession,
updateSessionMessages,
deleteSession,
selectSession,
newChat,
} = useChatSessions(currentUser?.id ?? null);
// 聊天 hook
const { messages, sendMessage, status, setMessages, stop } = useChat({
id: currentSessionId || undefined,
});
// 当消息变化时,同步到会话
useEffect(() => {
if (currentSessionId && messages.length > 0) {
updateSessionMessages(currentSessionId, messages);
}
}, [messages, currentSessionId, updateSessionMessages]);
// 切换会话时,加载对应的消息
useEffect(() => {
if (currentSession) {
setMessages(currentSession.messages);
} else {
setMessages([]);
}
}, [currentSessionId, setMessages]);
// ...
}8.5 发送多模态消息
构建包含文本和图片的多模态消息(app/page.tsx):
const handleSubmit = useCallback(
async (message: { text: string }) => {
if (!message.text.trim() && pendingImages.length === 0) return;
// 将 userId 存入 cookie,供 API Route 读取
document.cookie = `membox_user_id=${userId}; path=/; max-age=86400`;
// 构建包含图片和文本的 parts 数组
const parts: Array<
{ type: 'text'; text: string } |
{ type: 'file'; mediaType: string; url: string }
> = [];
// 先添加图片
for (const url of pendingImages) {
parts.push({
type: 'file' as const,
mediaType: 'image/png',
url: url,
});
}
// 再添加文本
parts.push({
type: 'text' as const,
text: message.text || 'Please describe these images',
});
// 清空待发送的图片
setPendingImages([]);
// 发送消息到 /api/chat,由 API Route 调用 LLM
await sendMessage({ parts });
},
[sendMessage, userId, pendingImages]
);8.6 调用 LLM 生成回复
app/api/chat/route.ts 是前端的核心 API Route,负责:
- 搜索记忆:调用后端
/api/memory/search获取相关记忆和用户画像。 - 调用 LLM:将记忆上下文注入 System Prompt,调用千问模型生成回复。
- 保存记忆:在 LLM 回复完成后,调用后端
/api/memory/add保存记忆。
import { convertToModelMessages, streamText, consumeStream, UIMessage } from 'ai';
import { createOpenAICompatible } from '@ai-sdk/openai-compatible';
// 创建 Qwen 客户端(兼容 OpenAI 协议)
const qwen = createOpenAICompatible({
name: 'qwen',
apiKey: process.env.DASHSCOPE_API_KEY,
baseURL: 'https://dashscope.aliyuncs.com/compatible-mode/v1',
});
export async function POST(req: Request) {
// 接收前端发送的对话历史(包含 parts 格式的多模态消息)
const { messages }: { messages: UIMessage[] } = await req.json();
// 从 cookie 获取用户 ID
const cookies = req.headers.get('cookie') || '';
const userIdMatch = cookies.match(/membox_user_id=([^;]+)/);
const userId = userIdMatch?.[1] ?? 'default_user';
// 获取最后一条用户消息的文本
const lastMessage = messages.at(-1);
const lastMessageText = lastMessage?.parts?.find((p) => p.type === 'text')?.text ?? '';
// 检测是否有图片,选择对应模型
const hasImages = messages.some((m) => m.parts?.some((p) => p.type === 'file'));
const modelName = hasImages ? 'qwen-vl-plus' : 'qwen-plus';
// 1. 搜索相关记忆
const backendUrl = process.env.NEXT_PUBLIC_BACKEND_URL ?? 'http://localhost:8000';
let memoryContext = '';
try {
const searchRes = await fetch(`${backendUrl}/api/memory/search`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
query: lastMessageText,
user_id: userId,
limit: 5,
}),
});
if (searchRes.ok) {
const searchData = await searchRes.json();
// 用户画像
if (searchData.profile_content) {
memoryContext += `\nUser Profile: ${searchData.profile_content}`;
}
// 相关记忆
if (searchData.results?.length > 0) {
memoryContext += '\n\nRelated Memories:';
for (const mem of searchData.results) {
memoryContext += `\n- ${mem.memory}`;
}
}
}
} catch {
// 忽略记忆搜索错误
}
// 2. 构建 System Prompt,注入记忆上下文
const systemPrompt = `You are MemBox, an intelligent memory assistant...
${memoryContext ? `Here is background information:${memoryContext}` : ''}`;
// 3. 调用 LLM
const modelMessages = await convertToModelMessages(messages);
const result = streamText({
model: qwen.chatModel(modelName),
system: systemPrompt,
messages: modelMessages,
// 4. LLM 回复完成后保存记忆
async onFinish({ text }) {
const conversationToSave = [
{ role: 'user', content: lastMessageText || 'User shared images' },
{ role: 'assistant', content: text },
];
try {
await fetch(`${backendUrl}/api/memory/add`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
messages: conversationToSave,
user_id: userId,
}),
});
} catch {
// 忽略保存错误
}
},
});
return result.toUIMessageStreamResponse({ consumeSseStream: consumeStream });
}8.7 启动前端
安装依赖并启动前端服务:
cd frontend
pnpm install
pnpm dev访问 http://localhost:3000 访问页面。
输入用户名后即可开始聊天对话:
9. 效果演示
9.1 智能记忆
首先看看 PowerMem 的 Intelligent Memory(智能记忆) 功能:
👤 Seven:我是 Seven,在上海工作,喜欢踢足球
🤖 MemBox:嗨 Seven!上海的足球氛围挺不错的,黄浦区和徐汇区都有很多球场,周末经常能看到业余联赛。你平时都在哪个区域踢球呀?要是你喜欢的话,我还可以推荐几个不错的足球社群给你~
PowerMem 会将这些信息持久化存储到 SeekDB 中,即使会话结束也不会丢失,随时可以在后续对话中被智能检索和使用。
9.2 记忆检索
当用户发起新对话时,MemBox 会自动根据当前问题检索相关记忆。这是通过 SeekDB 的向量相似度搜索实现的——将用户问题转换为向量,在记忆库中找到语义最相近的内容。
下次对话时,即使用户没有明确提及之前说过的内容,MemBox 也能智能关联:
👤 Seven:周末有什么活动推荐?
🤖 MemBox:Hey Seven!既然你在上海而且喜欢踢足球,周未不如来场酣畅淋漓的球局吧!......
注意,Seven 并没有再次提到"足球",但 MemBox 自动检索到了之前记忆的兴趣爱好,并据此给出个性化推荐。
9.3 多模态记忆
MemBox 不仅能记住文字,还能理解和记忆图片内容。当用户上传图片时,前端会调用多模态 LLM(qwen-vl-plus)来理解图片,然后将理解结果作为记忆存储:
👤 Seven:[上传一张猫的照片] 这是我的猫咪小蓝
🤖 MemBox:哇,小蓝看起来好可爱!这只灰白相间的猫咪趴在柔软的毯子上,阳光洒在它身上,真是治愈系的画面。你一定很爱它吧?猫咪总是能带来温暖和放松的感觉,看着它安静的样子,心情都会变好呢~
LLM 不仅识别出了猫的品种(英短蓝猫),还将这些信息与用户关联存储。之后再问起时,MemBox 能准确回忆:
👤 Seven:我的宠物叫什么名字?
🤖 MemBox:你的宠物叫小蓝,是一只灰白相间的猫咪,特别喜欢趴在柔软的毯子上休息。
9.4 用户画像
PowerMem 最强大的功能之一是自动构建用户画像。每次对话后,系统会:
- 获取该用户现有的画像(如果有)。
- 分析新对话,提取新的用户信息。
- 调用 LLM 将新旧信息智能合并。
- 更新用户画像。
随着对话积累,画像越来越丰富:
👤 用户画像:
- 姓名:Seven
- 工作地点:上海
- 爱好:踢足球
- 宠物:英短蓝猫,名叫小蓝PowerMem 搜索返回的结果中会包含 profile_content 字段,将其注入到 LLM 的上下文中,让 AI 在回答时"认识"这个用户。
9.5 用户隔离
在多用户场景下,数据安全和隐私隔离至关重要。MemBox 通过 user_id 实现严格的用户隔离——每个用户只能访问自己的记忆,无法看到其他用户的数据。
用户 A(Seven)的对话:
👤 Seven:我最喜欢的编程语言是 Python
🤖 MemBox:收到!我已经记下来了:你最喜欢的编程语言是 Python。
用户 B(Jane)的对话:
👤 Jane:我最喜欢的编程语言是什么?
🤖 MemBox:你还没有告诉我你最喜欢的编程语言是什么呢!要不要现在告诉我,让我帮你记下来?
可以看到,Seven 的偏好不会泄露给 Jane。这是通过 user_id 在存储和检索时的过滤实现的: SeekDB 在底层会将 user_id 作为过滤条件,确保查询结果只包含当前用户的数据。
10. 总结
本文介绍了如何使用 SeekDB 和 PowerMem 构建一个多模态智能记忆系统 MemBox。通过 SeekDB 的向量检索能力和 PowerMem 的智能记忆提取,MemBox 能够自动从对话中提取关键信息、构建用户画像,并在后续对话中提供个性化回复。前端基于 Vercel AI SDK 实现了流式对话和多模态图片理解,后端通过 FastAPI 提供记忆存储和检索服务。整个系统还支持多用户隔离,确保每个用户的数据安全独立。
11. 参考资料
12 欢迎关注
