kube-apiserver
kube-apiserver 处理请求的流程是怎样的?
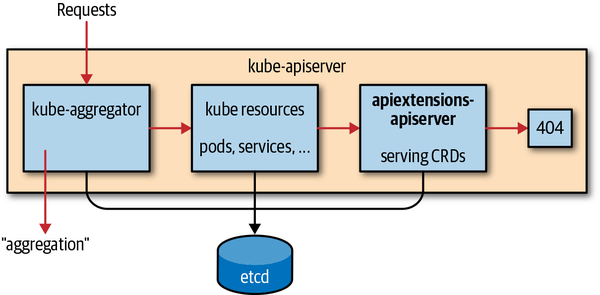
进入到 kube-apiserver 的请求会依次经历 4 个阶段:
- kube-aggregator:处理通过 APIService 注册的资源请求,将请求转发给 Aggregated API Server。
- kube resources:处理内置的 Pod, Service 等内置资源。
- apiextensions-apiserver:处理 CRD 资源的请求。
- 没有找到对应的资源,返回 404。
Kubernetes 的两种扩展机制 CRD 和 Aggregated API Server 有什么区别?
Aggregated API Server 相较于 CRD 更加灵活:
- 除了基本的 CRUD 操作,Aggregated API Server 还支持 log,exec 以及用户自定义的其他操作(如 metric-server 的 top 命令)。CRD 只支持 status 和 scale 两种 subresource。
- 可以使用 etcd 以外的存储后端。
- 实现更加复杂的要求,例如用户将资源提交给 Karmada 的 Aggregated API Server,资源不会在管理集群中创建,Karmanda 会将资源分发到多个工作集群中。
- CRD 不支持资源的优雅删除。
参考资料:
- K8s 的核心是 API 而非容器(一):从理论到 CRD 实践(2022)
- K8s 的核心是 API 而非容器(二):从开源项目看 k8s 的几种 API 扩展机制(2023)
- What is Aggregated API Server | Difference between Aggregated API Server and CRDs
- k8s crd和API Aggregation的区别
kube-scheduler
Scheduling Queue (调度队列)的工作原理是怎么样的?
调度器的 SchedulingQueue 接口的实现是一个 PriorityQueue 结构体,其中有 3 个子队列:
- ActiveQ(heap):存放就绪的 Pod,调度流程会从中取出 pod 进行调度。
- BackOffQ(heap):存放调度失败的 Pod,这里的 Pod 各自被设置了退避时间,等待足够的时间后才可以离开。
- unschedulablePods(map):存放调度失败且被判定为“无法调度成功”的 Pod,除非集群中发生了特定的事件或者 Pod 已达在子队列中阻塞时间的上限,否则 Pod 不会出队。
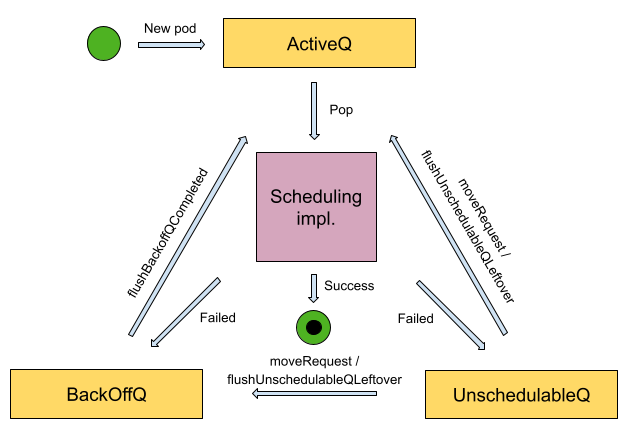
- AddUnschedulableIfNotPresent 默认会将调度或异步绑定失败的 Pod 添加到
unschedulablePods中,除非在 Pod 调度/绑定的过程中集群状态已经发生了变化。调度器通过schedulingCycle和moveRequestCycle两个变量来判断在 Pod 调度/绑定期间集群的状态是否发生了变化。(p.moveRequestCycle >= podSchedulingCycle)schedulingCycle,即PriorityQueue当前的调度轮次,当PriorityQueuepop 一个 Pod 时,该记录会加一。moveRequestCycle,即收到最近一次 moveRequest(movePodsToActiveOrBackoffQueue )时 PriorityQueue 所处的调度轮次,moveRequest 指的是从 UnschedulableQ 中移出特定的 Pod,可以理解为发起 moveRequest 就意味着“集群状态发生了变化”。- 结合起来,可以理解一下这里错误处理的细节。在 Pod 调度失败时,正常情况下,会被放进
unschedulablePods队列,但是在某些情况下,Pod 刚刚调度失败,在错误处理之前,忽然发生了资源变更,紧接着再调用错误处理回调,这个时候,由于在这个错误处理的间隙,集群的状态已经发生了变化,所以可以认为这个 Pod 应该有了被调度成功的可能性,所以就被放进了backoffQ重试队列中,等待快速重试。
- flushUnschedulablePodsLeftover 每隔 30s 运行一次, 将停留在
unschedulablePods中时间超过 DefaultPodMaxInUnschedulablePodsDuration (5 分钟)的 Pod 重新移动到backoffQ或者activeQ中。 - flushBackoffQCompleted 每隔 1s 运行一次,将在
backoffQ中已经完成退避时间的 Pod 重新移动到activeQ中。在默认情况下,当 Pod 第一次调度失败后,会等待 1s,然后重试,而在后续每次失败后,重试时间将会翻倍,即第二次失败等待 2s,第三次失败等待 4s,以此类推。此外,调度器设置了最长的 backoff 等待时间,在默认情况下,如果 Pod 连续调度失败,则其 backoff 等待时间最长为 10s。
我们可以举一个一般性的例子让 Pod 在 3 个子队列中完整地流转一遍。对于一个带有 NodeAffinity 强限制的 Pod,假设它从 ActiveQ 中出队尝试调度且因 NodeAffinity plugin 阻拦而调度失败。此时除非集群中已有节点发生状态(label)变化,否则对该 Pod 再次尝试调度是没有意义的,所以它应当先进入 unschedulablePods,直到产生了节点状态变化的事件才适时地将其放进 BackOffQ,随后等待达到 backOff 时间并进入 ActiveQ 中准备被再次调度。
参考资料:
- Kube-scheduler 源码分析之调度队列
- Scheduling queue in kube-scheduler
- Kubernetes 调度器队列 - 设计与实现
- k8s-src-analysis/kube-scheduler/SchedulingQueue.md
- k8s源码分析 2: kube-scheduler
- 深入理解 Kubernetes 源码 P432 ~ P433
Scheduling Framework (调度框架)提供的扩展点有哪些?
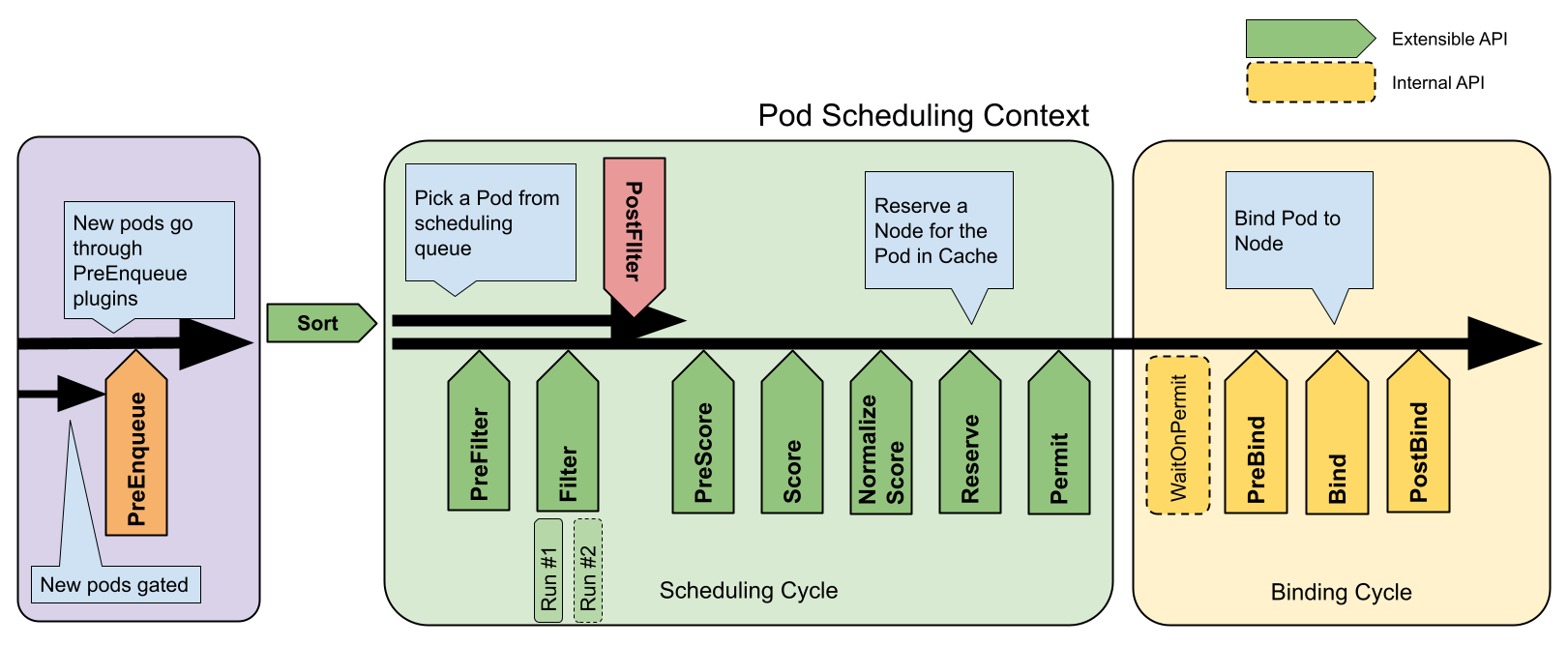
Scheduling Framework 通过 Plugin API 定义了多个扩展点,调度插件能够通过实现对应扩展点的 API 接口,注册到调度器框架中,在合适的时机被调用。 Scheduler Framework 提供了丰富的扩展点,如上图所示,包括:
- PreEnqueue 插件在 v1.27 版本引入,在 Pod 进入
activeQ队列之前被调用,仅将符合条件的 Pod 放入活动队列(Pod 的spec.schedulingGates字段为空),否则直接放入unschedulablePods队列中。 - QueueSort 插件用于处理 Pod 在调度队列中的排序顺序。
QueueSort插件需要实现Less函数,该函数用于比较两个 Pod 的大小,以便调度器能够对等待调度的 Pod 进行排序。默认调度器使用的是PrioritySort插件,顾名思义是按照 Pod 的优先级进行排序,优先级高的 Pod 会被优先调度。如果优先级相同,则时间戳较早的 Pod 会被优先调度。注意,在一个调度器中,只能启用一个QueueSort插件。 - PreFilter 插件主要用于实现
Filter之前的预处理,如根据待调度的 Pod 计算Filter阶段需要使用的调度相关信息,或者检查 Pod 依赖的集群状态必须满足的调度要求,在需求不满足时提前退出,避免无效调度。如果PreFilter插件返回错误,则调度过程会立即终止,后续的调度过程将不再执行。由于PreFilter插件在每个 Pod 调度过程中只执行一次,而Filter会对每个节点执行一次,因此一般将仅与 Pod 相关的计算逻辑前置到PreFilter阶段进行(比如 Fit 插件在PreFilter阶段计算 Pod 的资源请求),通过 Scheduling Context(CycleState)将预计算结果传递给Filter函数,避免Filter阶段产生大量重复计算。 - Filter 插件执行预选主逻辑,即选出能够运行待调度 Pod 的目标节点。对于每个节点,调度器会按照配置顺序依次执行
Filter插件,如果有任意一个Filter插件将当前节点标记为不可调度,则该节点被认定为不符合调度要求,后续的调度过程将不再执行。由于对节点是否符合调度要求而言,不同节点之间是相互不影响的,因此针对不同节点的预选是并行执行的,默认调度器会启动 16 个协程分片处理。 - PostFilter 插件仅在
Filter插件没有筛选出合适的节点的条件下才会被调用。一个典型的PostFilter插件实现就是 Pod 驱逐抢占,它通过驱逐节点上优先级更低的 Pod,使节点能够运行当前待调度的高优先级 Pod。PostFilter在实现上会根据Filter阶段产生的节点过滤结果,默认的内置驱逐插件会根据Filter的失败原因,即Unschedulable或UnschedulableAndUnresolvable快速确定能否通过驱逐 Pod 使目标节点变得可调度。PostFilter插件按照配置顺序依次执行,当某个插件将一个节点标记为可调度时,PostFilter插件调度过程结束,后续的PostFilter插件将不会被调用。 - PreScore 插件与
PreFilter类似,主要用于执行Score的前置准备任务,如预处理 Pod 在打分阶段需要用到的相关信息。如果PreScore插件返回错误,则调度过程会立即终止,后续的调度过程将不再执行。由于PreScore插件在每个 Pod 被调度时只执行一次,而Score需要分别针对每个候选节点执行一次,因此一般将仅与 Pod 相关的计算逻辑前置到PreScore阶段进行,通过 Scheduling Context(CycleState)将预计算结果传递给Score函数,避免Score阶段产生大量重复计算。 - NormalizeScore 插件用于在对节点进行最后的打分排名前,对得分进行归一化处理。归一化的用意在于,将不同插件的打分统一到 [0,100] 的区间范围,使各个
Score插件对最终的得分的影响程度尽可能相同。由于NormalizeScore主要用于对Score的打分结果进行修改,因此在实现上会作为Score插件的ScoreExtensions扩展存在。 - Reserve 插件主要用于为即将调用的 Pod 在目标节点上预留资源(例如 VolumeBinding 插件假定 PVC 和 PV 绑定并更新 PV 缓存),主要是为了防止 kube-scheduler 在等待绑定的成功前出现争用的情况(因为绑定是异步执行的,调度下一个 Pod 可能发生在绑定完成之前)。实现
Reserve扩展点的插件需要实现两个接口:Reserve和UnReserve。如果Reserve插件调用成功,则UnReserve默认不会被调用。如果调用成功后需要对运行时状态进行更新,可以选择在PostBind阶段执行对应的更新逻辑。UnReserve的调用时机除了Reserve执行失败,在之后的任意一个阶段调用失败,都会触发执行。 - Permit 插件在调度决策完成但还没有发起绑定流程时被调用,用于阻止或延迟绑定流程的执行。
Permit插件可以在多 Pod 协同调度场景中,确保相关的一组 Pod 能够同时被调度,这在一些大数据和机器学习的使用场景中比较常见。 - PreBind 插件用于执行绑定前的准备工作,例如,提供网络存储卷并挂载到目标节点,以便 Pod 能够在被调度到节点上后正常启动。
- Bind 插件通过向 api-server 发起 Bind 请求,真正执行 Pod 和节点的绑定操作。
- PostBind 插件在 Pod 绑定完成后被调用,主要用于执行通知或清理操作。
参考资料
- k8s-src-analysis/kube-scheduler/Plugin.md
- 深入理解 Kubernetes 源码 P446 ~ P452
kubelet
1 kubelet 的作用是什么?
kubelet 是 Kubernetes 中最重要的节点代理程序,运行在集群中的每个节点上。它能够自动将节点注册到 Kubernetes 集群,将节点、Pod 的运行状态和资源使用情况周期性地上报至 kube-apiserver,同时接收 kube-apiserver 下发的工作任务、启动或停止容器、维护和管理 Pod。
2 Kubelet 获取 Pod Spec 的来源有哪些?
Kubelet 获取 Pod Spec 的来源有 3 种,即 kube-apiserver、File 和 HTTP:
- kube-apiserver 是 Kubelet 获取 Pod Spec 的主要来源,Kubelet 通过 Informer List-Watch 机制持续获取来自 kube-apiserver 的 Pod 变化事件,触发执行 sync 调谐。
- File 和 HTTP 主要用于发现 Static Pod,Kubelet 默认每隔 20 秒执行一次检测,重新从 File 或 HTTP 地址加载 Pod Spec。为了加速配置变更检测的速度,对于 Linux 下 file 类型的 Static Pod,Kubelet 支持通过 fsnotify 方式 Watch 指定文件夹下的变更事件。
- File 通过
staticPodPath配置指定 Static Pod 配置文件的路径(以前是--pod-manifest-path参数),默认监听的文件夹地址是/etc/kubernetes/manifests;HTTP 通过staticPodURL配置指定 Static Pod 配置文件的 URL(以前是--manifest-url参数)。
参考资料:深入理解 Kubernetes 源码 P596
3 PLEG 是什么?
PLEG(Pod Lifecycle Event Generator)是 kubelet 的一个重要核心组件,负责监控 kubelet 管理的节点上运行的 Pod 的生命周期,并生成与生命周期有关的事件。
4 PLEG 产生的原因是什么?
在 Kubernetes 中,kubelet 负责维护和管理每个节点上的 Pod,不断调谐 Pod 的状态(Pod Status)以使其符合定义的要求(Pod Spec)。在引入 PLEG 之前,为了监听 Pod Status 的变化,每个 Pod 的处理协程(Pod Worker)都会独立地周期性地为所有容器拉取最新状态来获取变化。这种轮询会产生不可忽略的开销,而且会随着 Pod 数量的增加而不断增大,从而导致过高的 CPU 占用,降低节点的处理性能,甚至由于对容器运行时产生过大的压力而出现稳定性问题。
参考资料:深入理解 Kubernetes 源码 P652
5 PLEG 的核心功能和架构
PLEG 主要包含两个核心功能:一是感知容器变化,生成 Pod 事件,而是维持一份最新的 Pod Status Cache 数据以供其他组件读取,其架构设计如下图所示。
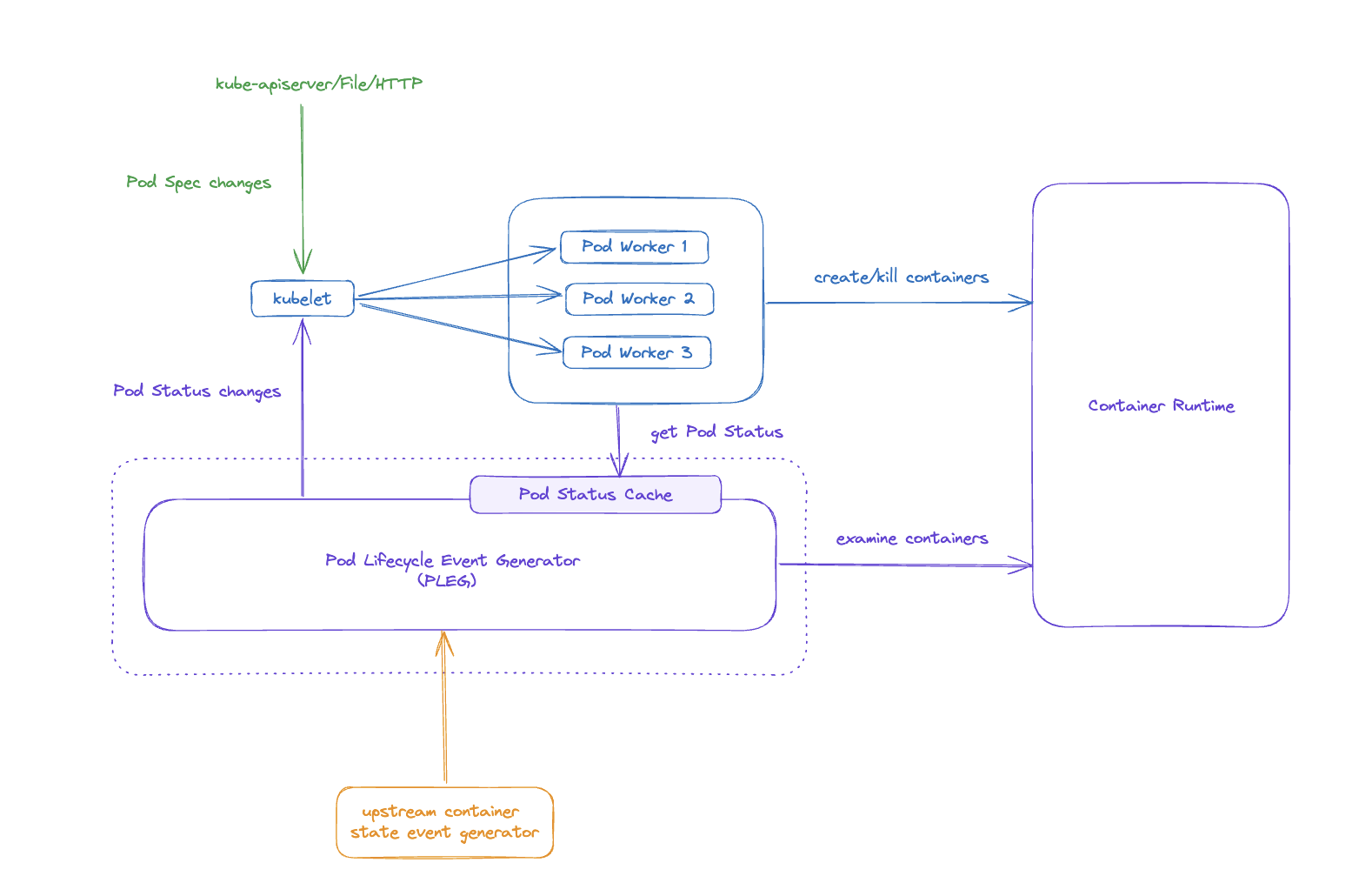
kubelet 同时接收两个方向的事件,Pod Spec 有 kube-apiserver、File、HTTP 三大来源,而 Pod Status 则来自 PLEG。 无论是收到 Pod Spec 变化,还是收到 Pod Status 变化,都会触发对应 Pod Worker 执行 Reconcile 调谐逻辑,使 Pod Status 符合最新的 Spec 定义。 Pod Worker 在执行调谐的过程中,会读取由 PLEG 维护的最新的 Pod Status,以避免直接向容器运行时发起请求,降低容器运行时的压力,同时提高状态读取效率。
在 v1.25 版本的 kubelet 中,PLEG 仅实现了基于周期性(当前的硬编码默认值是 1s)relist 方式的容器事件生成,从 v1.26 版本开始,kubelet 引入了 Evented PLEG,并且在 v1.27 版本进入 beta 阶段,实现了对接上游容器状态事件生成器的功能,以支持对上游容器运行时的事件监听,减少 relist 的开销,并且提高事件响应速度。由于 Evented PLEG 依赖 CRI Runtime 的支持,默认处于关闭状态,因此需要显式开启 EventedPLEG feature gate 才能使用该功能。
参考资料:
- 深入理解 Kubernetes 源码 P653
- KEP-3386: Kubelet Evented PLEG for Better Performance
6 kubelet 的主程序核心处理流程
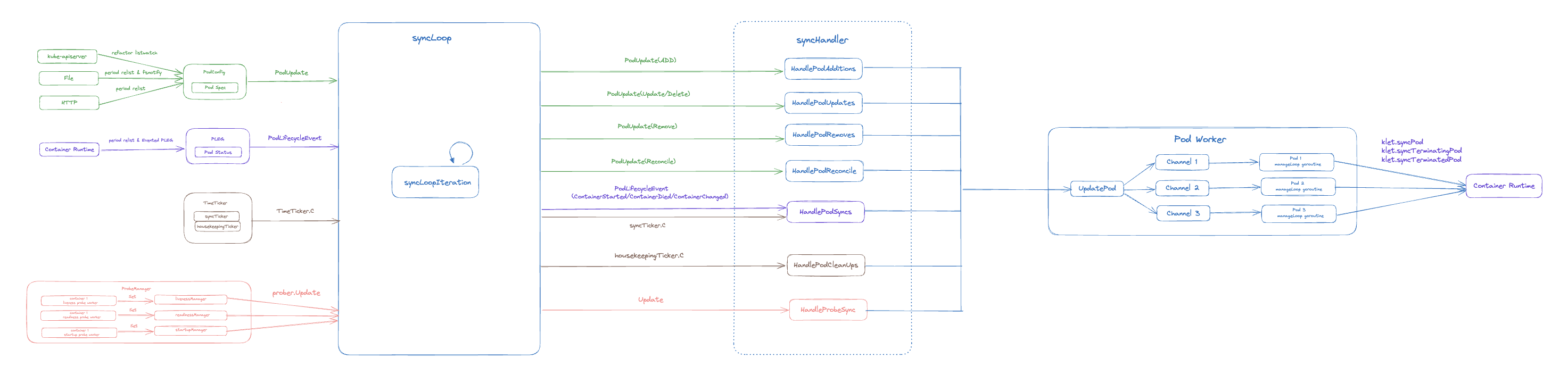
kubelet 的主调谐程序 syncLoop 同时监听来自不同组件的事件,包括:
- 来自 kube-apiserver、File、HTTP 的 Pod Spec 变化事件
- 来自 PLEG 的 Pod Status 变化事件
- 来自 ProbeManager(包括 liveness、readiness、startup 3 种健康探针)的状态变更事件
- 内置定时器(TimeTicker)事件
为了保证所有事件都能及时得到处理,kubelet 的主调谐程序采用了非阻塞的基于事件的处理模式。在事件源方面,所有的事件监听程序采用独立协程运行,将产生的事件通过相应 Channel 传递给 syncLoopIteration 函数进行处理。
syncLoopIteration 可以看作是一个事件分发器,它同时监听来自多个 Channel 的事件,根据事件类型的不同,分别执行不同的 SyncHandler 函数。
为了实现主调谐程序的非阻塞运行,kubelet 对事件的处理同样采用了异步执行的方式。对于每个 Pod,kubelet 会通过 Pod Worker 单独为其创建一个 goroutine,由每个 goroutine 独立处理对应 Pod 的变更事件。
参考资料:深入理解 Kubernetes 源码 P598
其他
Pod 的终止流程
- Pod 被删除,状态变为 Terminating。从 API 层面看就是 Pod metadata 中的 deletionTimestamp 字段会被标记上删除时间。
- Endpoint Controller 会将 Pod 从 Service 的 endpoint 列表中摘除掉,kube-proxy 根据 endpoint 更新转发规则,新的流量不再转发到该 Pod。
- kubelet watch 到了就开始销毁 Pod。
- 如果 Pod 中有 container 配置了 preStop Hook ,将会执行。
- 发送 SIGTERM 信号给容器内主进程以通知容器进程开始优雅停止。
- 等待 container 中的主进程完全停止,如果在
terminationGracePeriodSeconds内 (默认 30s) 还未完全停止,就发送 SIGKILL 信号将其强制杀死。 - 所有容器进程终止,清理 Pod 资源。
- 通知 API Server Pod 销毁完成,完成 Pod 删除。
参考资料:
Pause 容器有什么用?
在 Kubernetes 中,pause 容器充当 Pod 中所有容器的“父容器”。pause 容器有两个核心职责:
- 首先,它作为 Pod 中 Linux 命名空间共享的基础。
- 其次,在启用 pid(Process ID)命名空间共享的情况下,它充当每个 Pod 的 pid 1 并负责回收容器的僵尸进程。
参考资料:
Kubernetes 对象版本控制 ResourceVersion 和 Generation 区别
- ResourceVersion 基于底层 etcd 的 revision 机制,资源对象每次更新时都会改变,且集群范围内唯一,用于乐观并发控制。
- Generation 初始值为 1,随对象 Spec 内容的改变而自增。
故障案例
解决 kube-apiserver 流量不均衡问题
由于 API Server 和 client 是使用 HTTP2 协议连接,HTTP2 的多个请求都会复用底层的同一个 TCP 连接并且长时间不断开。而在 API Server 发生 RollingUpdate 或者某个 API Server 实例重启时,又或者 API Server 使用 MaxSurge=Replica 方式升级后, Load Balance 没有及时的将所有副本挂载完毕,client 能敏感的感知到连接的断开并立刻发起新的请求,这时候很容易引起较后启动(或者较后挂载 Load Balance)的 API Server 没有一点流量,并且可能永远都得不到负载均衡。
在 Kubernetes 1.18 版本中,增加了一种通用的 HTTP filter,API Server 概率性(建议 1/1000)的随机关闭和 Client 的链接(向 Client 发送 GOAWAY)。关闭是优雅的关闭,不会影响 API Server 和 client 正在进行中的长时间请求(如 Watch 等),但是收到 GOAWAY 之后,client 新的请求就会重新建立一个新的 TCP 链接去访问 API Server 从而能让 Load Balance 再做一次负载均衡。可以在 kube-apiserver 的配置中添加 --goaway-chance 参数进行设置。
spec:
containers:
- command:
- kube-apiserver
- --advertise-address=x.x.x.x
- --basic-auth-file=/xxx/user
- --bind-address=0.0.0.0
- --feature-gates=ExpandInUsePersistentVolumes=true,VolumeSnapshotDataSource=true
- --client-ca-file=/xxx/ca.crt
- --enable-admission-plugins=NodeRestriction
- --enable-bootstrap-token-auth=true
- --endpoint-reconciler-type=lease
- ...
- --goaway-chance=0.001 # 1/1000 的概率断开连接另外也可以考虑使用字节跳动开源的针对 kube-apiserver 流量特征专门定制的七层网关,它彻底解决了 kube-apiserver 负载不均衡的问题,同时在社区范围内首次实现了对 kube-apiserver 请求的完整治理,包括请求路由、分流、限流、降级等,显著提高了 Kubernetes 集群的可用性。
参考资料:
- API Server 负载均衡问题被解决 | 云原生生态周报 Vol. 40
- 解决Kubernetes APIServer流量不均衡问题
- 字节跳动 kube-apiserver 高可用方案 KubeGateway
最佳实践
etcd
- 高可用部署。部署一个高可用 etcd 集群可以参考官方文档 Clustering Guide。
- 使用 SSD 固态硬盘提高磁盘 IO 性能。 etcd 对磁盘写入延迟非常敏感,对于负载较重的集群建议磁盘使用 SSD 固态硬盘。可以使用 diskbench 或 fio 测量磁盘实际顺序 IOPS。
- 提高 etcd 的磁盘 IO 优先级。 由于 etcd 必须将数据持久保存到磁盘日志文件中,因此来自其他进程的磁盘活动可能会导致增加写入时间,结果导致 etcd 请求超时和临时 leader 丢失。当给定高磁盘优先级时,etcd 服务可以稳定地与这些进程一起运行:
sudo ionice -c2 -n0 -p $(pgrep etcd)- 提高存储配额:默认 etcd 空间配额大小为 2G,超过 2G 将不再写入数据。通过给 ETCD 配置 --quota-backend-bytes 参数增大空间配额,最大支持 8G。
- 分离 event 存储。集群规模大的情况下,集群中包含大量节点和服务,会产生大量的 event,这些 event 将会对 etcd 造成巨大压力并占用大量 etcd 存储空间,为了在大规模集群下提高性能,可以将 events 存储在单独的 etcd 集群中。
--etcd-servers="http://etcd1:2379,http://etcd2:2379,http://etcd3:2379" --etcd-servers-overrides="/events#http://etcd4:2379,http://etcd5:2379,http://etcd6:2379"- 减小网络延迟。 如果有大量并发客户端请求 etcd leader 服务,则可能由于网络拥塞而延迟处理 follower 对等请求。在 follower 节点上的发送缓冲区错误消息:
dropped MsgProp to 247ae21ff9436b2d since streamMsg's sending buffer is full
dropped MsgAppResp to 247ae21ff9436b2d since streamMsg's sending buffer is full可以通过在客户端提高 etcd 对等网络流量优先级来解决这些错误。在 Linux 上,可以使用 tc 对对等流量进行优先级排序:
tc qdisc add dev eth0 root handle 1: prio bands 3
tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip sport 2380 0xffff flowid 1:1
tc filter add dev eth0 parent 1: protocol ip prio 1 u32 match ip dport 2380 0xffff flowid 1:1
tc filter add dev eth0 parent 1: protocol ip prio 2 u32 match ip sport 2379 0xffff flowid 1:1
tc filter add dev eth0 parent 1: protocol ip prio 2 u32 match ip dport 2379 0xffff flowid 1:1参考资料:
- ETCD 优化
- Scaling Kubernetes: Best Practices for Managing Large-Scale Batch Jobs with Spark and Argo Workflow
kube-apiserver
- 流量控制:
- 客户端(kube-scheduler, controller, kubelet 等):调优 qps/brust 参数,在大型集群中,建议增加这些参数,以防止客户端因请求过多而被限制,从而导致请求失败或延迟。
- 服务端(kube-apiserver):调优 APF 流量控制策略方式 kube-apiserver 由于大量请求而瘫痪。
- 高可用部署: 使用多个 kube-apiserver 实例,通过负载均衡器进行负载均衡,提高可用性。根据资源使用量对 kube-apiserver 进行 HPA 或者 VPA 扩展。
- 使用 GoAway 机制解决流量不均衡的问题:在 kube-apiserver 的配置中添加
--goaway-chance=0.001参数,随机断开已存在的 TCP 长链接,以解决 kube-apiserver 滚动更新后可能产生的流量不均衡问题,避免单个 kube-apiserver 请求过载。 - 当对小于等于 Kubernetes 1.30 版本的集群使用 LIST 操作时,建议设置
resourceVersion=0参数从 api-server 中获取缓存数据,避免对 etcd 的全量请求。Kubernetes 1.31 版本开始,不设置resourceVersion参数也会默认从缓存中获取数据。
参考资料: