如何限制协程执行数量?
在 Go 中,当我们需要同时执行大量的协程时,可能会因为资源(如 CPU 或内存)的限制,导致性能下降甚至系统崩溃。因此,限制协程的执行数量是控制并发度、提高程序效率的重要手段。
我们可以通过带缓冲的 channel 来控制协程的并发数量。缓冲区大小决定了同时允许多少个协程执行,超出的协程会阻塞,直到有其他协程完成。
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var wg sync.WaitGroup
maxWorkers := 3
sem := make(chan struct{}, maxWorkers) // 通过带缓冲的 channel 来控制协程的并发数量
// 启动 10 个协程,但最多只会有 maxWorkers 个协程同时执行
for i := 0; i < 10; i++ {
wg.Add(1)
go worker(i, &wg, sem)
}
// 等待所有协程完成
wg.Wait()
}
func worker(id int, wg *sync.WaitGroup, sem chan struct{}) {
defer wg.Done()
sem <- struct{}{} // 获取信号
defer func() {
<-sem
}() // 释放信号
fmt.Printf("Worker %d is working\n", id)
time.Sleep(2 * time.Second) // 模拟工作
fmt.Printf("Worker %d done\n", id)
}
// 输出结果
//Worker 9 is working
//Worker 6 is working
//Worker 4 is working
//Worker 4 done
//Worker 5 is working
//Worker 9 done
//Worker 2 is working
//Worker 6 done
//Worker 0 is working
//Worker 0 done
//Worker 7 is working
//Worker 5 done
//Worker 8 is working
//Worker 2 done
//Worker 3 is working
//Worker 3 done
//Worker 1 is working
//Worker 7 done
//Worker 8 done
//Worker 1 done函数执行超时控制代码怎么写?
在 Go 中,可以使用 context 包来实现函数执行的超时控制。context.WithTimeout 可以创建一个带有超时的上下文,当超时时间达到时,函数会停止执行。
select 语句用于同时监听任务执行结果和超时信号。如果任务完成,则输出结果;如果超过 2 秒任务未完成,ctx.Done() 会触发超时处理。
package main
import (
"context"
"fmt"
"time"
)
// 模拟一个长时间运行的任务
func longRunningTask(resultChan chan<- string) {
fmt.Println("Task is running")
time.Sleep(1 * time.Second)
resultChan <- "Task is completed"
}
func main() {
resultChan := make(chan string, 1)
// 设置超时为2秒
ctx, cancel := context.WithTimeout(context.Background(), 2*time.Second)
defer cancel() // 保证资源被释放
// 启动一个 goroutine 执行任务
go longRunningTask(resultChan)
// 使用 select 等待任务完成或超时
select {
case result := <-resultChan:
fmt.Println(result)
case <-ctx.Done():
fmt.Println("Timeout: Task took too long")
}
}sync.Pool 有什么用?
sync.Pool 是一个对象缓存池,可以用来存储临时对象,减少对象的创建和销毁次数,提高性能。sync.Pool 是并发安全的,可以在多个 goroutine 中并发使用。 使用方法:
Get():从池中获取一个对象,如果池是空的,则调用 New 创建新对象。Put():将对象放回池中,以便复用。
package main
import (
"fmt"
"sync"
)
type User struct {
Name string
}
func main() {
p := &sync.Pool{
New: func() interface{} {
fmt.Println("Creating a new User")
return &User{Name: "Seven"}
},
}
// 从池中获取一个对象,如果池是空的,则调用 New 创建新对象
u1 := p.Get().(*User)
println(u1.Name)
u1.Name = "Jack"
// 将对象放回池中,以便复用
p.Put(u1)
u2 := p.Get().(*User)
println(u2.Name)
}
// 输出结果,只创建了一次 User 对象
//Creating a new User
//Seven
//Jack像 gin 框架中的 Context 对象就是使用 sync.Pool 来复用的。(代码:ServeHTTP)
// ServeHTTP conforms to the http.Handler interface.
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) {
// 从 sync.Pool 中获取一个 Context 对象
c := engine.pool.Get().(*Context)
c.writermem.reset(w)
c.Request = req
c.reset()
engine.handleHTTPRequest(c)
engine.pool.Put(c)
}明明是 nil 却 != nil 的问题
在下面的代码中,虽然变量 a 是 nil,但是在将它赋值给 b(interface{} 类型)之后,b 并 不是 nil。这是因为在 Go 中,interface{} 类型的值由两部分组成:
- 类型(type):存储的是具体值的类型。
- 值(value):存储的是具体的值。
当你将 a 赋值给 b 时,b 是一个接口类型,它会包含两部分信息:
- 类型部分是
*struct{}(即 b 的类型是*struct{})。 - 值部分是 nil(因为 a 是一个 nil 指针)。
但是,在 Go 中,一个接口只有在其“类型”和“值”都为 nil 时,才被认为是 nil。在你的代码中,b 的类型是 *struct{},虽然它的值是 nil,但它的类型部分并不是 nil,因此 b != nil。
package main
import "fmt"
func main() {
var a *struct{}
var b interface{} = a
if b == nil {
fmt.Println("b is nil")
} else {
fmt.Println("b is not nil")
}
}
// 打印结果
//b is not nilvar data []int 和 var data = make([]int, 0) 有什么区别?
var data []int 声明一个切片,初始值为 nil。 var data = make([]int, 0) 切片的值不为 nil,而是一个长度和容量都为 0 的空切片。在大多数情况下,推荐使用 var data = make([]int, 0) 来初始化切片。
在容器和 Kubernetes 集群中,存在 GOMAXPROCS 会错误识别容器 CPU 核心数的问题
默认情况下,Golang 会将 GOMAXPROCS 设置为 CPU 核心数,这允许 Golang 程序充分使用机器的每一个 CPU,最大程度的提高我们程序的并发性能。 但是在容器中,runtime.GOMAXPROCS() 获取的是 宿主机的 CPU 核数 。P 值设置过大,导致生成线程过多,会增加上线文切换的负担,导致严重的上下文切换,浪费 CPU。
解决方案是可以使用 automaxprocs,大致原理是读取 CGroup 值识别容器的 CPU quota,计算得到实际核心数,并自动设置 GOMAXPROCS 线程数量。
import _ "go.uber.org/automaxprocs"
func main() {
// Your application logic here
}参考资料:
两个 goroutine 交替打印字母和数字
package main
import (
"fmt"
"sync"
"time"
)
func main() {
num := make(chan struct{})
letter := make(chan struct{})
wg := sync.WaitGroup{}
wg.Add(1)
go func() {
i := 1
for {
select {
case <-num:
fmt.Print(i)
i++
time.Sleep(time.Millisecond * 200)
letter <- struct{}{}
}
}
}()
go func() {
j := 'a'
for {
select {
case <-letter:
fmt.Print(string(j))
if j == 'z' {
wg.Done()
}
j++
time.Sleep(time.Millisecond * 200)
num <- struct{}{}
}
}
}()
// 先打印数字
num <- struct{}{}
wg.Wait()
}
// 打印结果
1a2b3c4d5e6f7g8h9i10j11k12l13m14n15o16p17q18r19s20t21u22v23w24x25y26z%两个 goroutine 并发更新数字
要实现两个 goroutine 并发更新同一个数字,并且保证数据的正确性,我们需要使用同步原语来避免竞争条件(Race Condition)。Go 语言提供了 sync.Mutex 或者 sync/atomic 包来实现并发安全的数据访问。
方式 1: 使用 sync.Mutex
sync.Mutex 是互斥锁,用于在多 goroutine 中同步访问共享资源,确保同一时间只有一个 goroutine 可以对共享资源进行修改。
package main
import (
"fmt"
"sync"
)
func main() {
var num int
var mu sync.Mutex // 用来保护共享变量 num
wg := sync.WaitGroup{}
// 启动两个 goroutine
wg.Add(2)
// 第一个 goroutine
go func() {
defer wg.Done()
for i := 0; i < 1000; i++ {
mu.Lock()
num++
mu.Unlock()
}
}()
// 第二个 goroutine
go func() {
defer wg.Done()
for i := 0; i < 1000; i++ {
mu.Lock()
num++
mu.Unlock()
}
}()
// 等待两个 goroutine 完成
wg.Wait()
fmt.Println("最终的 num 值:", num)
}解释:
- 互斥锁 (
sync.Mutex):确保在任意时刻,只有一个 goroutine 可以修改num。 - 每个 goroutine 循环 1000 次,每次递增
num。 wg.Wait()等待两个 goroutine 完成。
方式 2: 使用 sync/atomic
sync/atomic 提供了一些低级的原子操作,适合并发环境下对单个变量的安全访问和修改。
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main() {
var num int64 // 使用 int64,因为 atomic 需要操作 64 位的整数
wg := sync.WaitGroup{}
// 启动两个 goroutine
wg.Add(2)
// 第一个 goroutine
go func() {
defer wg.Done()
for i := 0; i < 1000; i++ {
atomic.AddInt64(&num, 1) // 原子操作
}
}()
// 第二个 goroutine
go func() {
defer wg.Done()
for i := 0; i < 1000; i++ {
atomic.AddInt64(&num, 1) // 原子操作
}
}()
// 等待两个 goroutine 完成
wg.Wait()
fmt.Println("最终的 num 值:", num)
}解释:
atomic.AddInt64:这是一个原子操作,确保多个 goroutine 并发访问时的安全性。- 和使用互斥锁相比,
atomic操作的性能更好,但只适用于简单的原子操作。
总结:
- 使用
sync.Mutex:适合较复杂的操作,确保代码块内的操作在多 goroutine 环境下安全执行。 - 使用
sync/atomic:适合简单的变量更新操作,性能较好。
sync.Cond 的使用场景
sync.Cond 经常用在多个 goroutine 等待,一个 goroutine 通知(事件发生)的场景。如果是一个通知,一个等待,使用互斥锁或 channel 就能搞定了。
package main
import (
"fmt"
"sync"
"time"
)
func read(name string, c *sync.Cond) {
// 每个 Cond 实例都会关联一个锁 L(互斥锁 *Mutex,或读写锁 *RWMutex),当修改条件或者调用 Wait 方法时,必须加锁。
c.L.Lock()
c.Wait()
fmt.Println(name, "start reading")
c.L.Unlock()
}
func write(name string, c *sync.Cond) {
fmt.Println(name, "start writing")
time.Sleep(time.Second * 1)
fmt.Println("wakes all")
c.Broadcast()
}
func main() {
cond := sync.NewCond(&sync.Mutex{})
go read("reader1", cond)
go read("reader2", cond)
go read("reader3", cond)
write("writer", cond)
time.Sleep(time.Second * 3)
}
// 打印结果
writer start writing
wakes all
reader3 start reading
reader1 start reading
reader2 start readingsync.Once 使用场景
sync.Once 是 Go 标准库提供的使函数只执行一次的实现,常应用于单例模式,例如初始化配置、保持数据库连接等。作用与 init 函数类似,但有区别。
- init 函数是当所在的 package 首次被加载时执行,若迟迟未被使用,则既浪费了内存,又延长了程序加载时间。
- sync.Once 可以在代码的任意位置初始化和调用,因此可以延迟到使用时再执行,并发场景下是线程安全的。
package main
import (
"fmt"
"sync"
)
// Config 是一个模拟的配置结构体
type Config struct {
Value string
}
// 定义一个全局的 Config 实例和 sync.Once 实例
var (
config Config
once sync.Once
)
// 初始化配置的函数
func initConfig() {
config = Config{Value: "Initialized Value"}
fmt.Println("Config initialized.")
}
// 获取配置的函数,确保配置只初始化一次
func getConfig() Config {
once.Do(initConfig) // 确保 initConfig 只被调用一次
return config
}
func main() {
var wg sync.WaitGroup
// 启动多个 goroutine,尝试获取配置
for i := 0; i < 5; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
cfg := getConfig()
fmt.Printf("Goroutine %d: %s\n", id, cfg.Value)
}(i)
}
wg.Wait() // 等待所有 goroutine 完成
}
// 打印结果
Config initialized.
Goroutine 1: Initialized Value
Goroutine 2: Initialized Value
Goroutine 3: Initialized Value
Goroutine 0: Initialized Value
Goroutine 4: Initialized ValueContext 使用场景
在 Go 语言中,context 包提供了一种在多个 goroutine 之间传递请求范围和截止日期的信息的方式。它常用于取消操作、超时控制和传递请求级别的值。以下是一些使用 context 的基本示例和最佳实践。
context.Background():通常在程序的入口点或最顶层的函数中使用,表示根上下文。context.WithCancel:用于创建可以被取消的上下文。context.WithTimeout:创建一个在指定时间后自动取消的上下文。context.WithDeadline:与超时上下文类似,但使用具体的截止时间。
以下是一个使用 context 的示例,演示如何在多个 goroutine 中传递取消信号和超时控制。
package main
import (
"context"
"fmt"
"time"
)
func worker(ctx context.Context, id int) {
select {
case <-time.After(2 * time.Second): // 模拟工作
fmt.Printf("Worker %d finished work\n", id)
case <-ctx.Done(): // 监听取消信号
fmt.Printf("Worker %d stopped\n", id)
}
}
func main() {
ctx, cancel := context.WithCancel(context.Background())
for i := 0; i < 5; i++ {
go worker(ctx, i)
}
// 如果小于 2s,worker 会来不及完成工作
time.Sleep(time.Second * 1)
// 取消上下文,所有监听 ctx.Done() 的 goroutine 将收到通知
cancel()
// 等待一段时间以查看结果
time.Sleep(3 * time.Second)
}下面是一个使用超时上下文的示例:
package main
import (
"context"
"fmt"
"time"
)
func worker(ctx context.Context, id int) {
select {
case <-time.After(2 * time.Second): // 模拟工作
fmt.Printf("Worker %d finished work\n", id)
case <-ctx.Done(): // 监听取消信号
fmt.Printf("Worker %d stopped\n", id)
}
}
func main() {
// 设置超时时间
ctx, cancel := context.WithTimeout(context.Background(), 1*time.Second)
defer cancel() // 确保在 main 退出时调用 cancel
for i := 0; i < 5; i++ {
go worker(ctx, i)
}
// 等待一段时间以查看结果
time.Sleep(3 * time.Second)
}如果函数 []int 类型切片参数在函数内部发生了扩容,对原切片有影响吗?
在 Go 中,切片是引用类型,传递给函数的是切片的引用。在函数内部对切片的修改会影响原切片,但是如果切片发生了扩容,函数内部的切片参数会引用新的数组,对切片的修改不会影响原切片。
不发生扩容:
- 当函数中的操作不导致切片扩容,切片参数和原切片会共享同一个底层数组。
- 在函数内部修改切片内容(例如 slice[i] = value),会直接影响传入的原始切片,因为它们指向同一个底层数组。
发生扩容:
- 当函数中的操作(如 append)导致切片容量超出当前容量限制时,Go 会创建一个新的更大容量的底层数组。
- 此时,函数内部的切片参数会引用新数组,对切片的修改不会影响原切片。
package main
import "fmt"
func modifySlice(slice []int) {
fmt.Printf("Before append: len=%d cap=%d address=%p\n", len(slice), cap(slice), slice)
// 追加元素使切片扩容
// slice 在函数内部指向新的数组,而 original 仍然指向原数组
// slice 在函数内部的修改就不会体现在 original 指向的原数组上了
// 如果 slice 切片没有扩容,那么在函数内部的修改也会体现在 original 上
slice = append(slice, 100)
fmt.Printf("After append: len=%d cap=%d address=%p\n", len(slice), cap(slice), slice)
// 修改切片内容
slice[0] = 999
}
func main() {
// 定义一个长度和容量较小的切片
original := []int{1, 2, 3}
fmt.Printf("Original slice: len=%d cap=%d address=%p\n", len(original), cap(original), original)
modifySlice(original)
fmt.Printf("After function call: len=%d cap=%d address=%p\n", len(original), cap(original), original)
fmt.Println("Original slice content:", original)
}
// 打印结果
Original slice: len=3 cap=3 address=0xc0000ae000
Before append: len=3 cap=3 address=0xc0000ae000
After append: len=4 cap=6 address=0xc0000b4030
After function call: len=3 cap=3 address=0xc0000ae000
Original slice content: [1 2 3]如果想要在切片扩容的情况下,在函数内部的修改也能体现在原切片上,可以使用指针传递切片。
package main
import "fmt"
func modifySlice(slice *[]int) {
fmt.Printf("Before append: len=%d cap=%d address=%p\n", len(*slice), cap(*slice), *slice)
// 追加元素,导致切片扩容
*slice = append(*slice, 100)
fmt.Printf("After append: len=%d cap=%d address=%p\n", len(*slice), cap(*slice), *slice)
// 修改切片内容
(*slice)[0] = 999
}
func main() {
original := []int{1, 2, 3}
fmt.Printf("Original slice: len=%d cap=%d address=%p\n", len(original), cap(original), original)
// 传入指针
modifySlice(&original)
fmt.Printf("After function call: len=%d cap=%d address=%p\n", len(original), cap(original), original)
fmt.Println("Original slice content:", original)
}
// 打印结果
Original slice: len=3 cap=3 address=0xc00001a018
Before append: len=3 cap=3 address=0xc00001a018
After append: len=4 cap=6 address=0xc00010a030
After function call: len=4 cap=6 address=0xc00010a030
Original slice content: [999 2 3 100]函数参数 struct 类型传值和传指针的区别
传值方式函数内部对结构体字段的修改不会影响原始结构体;而传指针可以直接修改原始结构体的数据,因为传递的是结构体的地址。
package main
import "fmt"
type Person struct {
name string
age int
}
func changeNameByValue(p Person) {
p.name = "Alice"
}
func changeNameByPointer(p *Person) {
p.name = "Alice"
}
func main() {
person1 := Person{name: "Bob", age: 25}
person2 := Person{name: "Bob", age: 25}
changeNameByValue(person1)
fmt.Println("After changeNameByValue:", person1.name) // 输出 "Bob"
changeNameByPointer(&person2)
fmt.Println("After changeNameByPointer:", person2.name) // 输出 "Alice"
}make 和 new 的区别是什么?
| 操作符 | 适用类型 | 功能 | 返回值类型 |
|---|---|---|---|
new | 所有类型 | 为类型分配内存并返回指向该类型零值的指针 | 指向零值类型的指针 |
make | slice、map、channel | 分配并初始化内存,返回已初始化的对象 | 已初始化的对象(非指针) |
make 返回的不是指针,主要是因为切片、映射和通道在 Go 中是引用类型,而它们的本质就是一个指向底层数据结构的指针。
对已经关闭的的 channel 进行读写,会怎么样?为什么?
- 读已经关闭的 channel 能一直读到东西,但是读到的内容根据通道内关闭前是否有元素而不同。
- 如果 channel 关闭前,buffer 内有元素还未读,会正确读到 channel 内的值,且返回的第二个 bool 值(是否读成功)为true。
- 如果 channel 关闭前,buffer 内有元素已经被读完,channel 内无值,接下来所有接收的值都会非阻塞直接成功,返回 channel 元素的零值,但是第二个 bool 值一直为 false。
- 写已经关闭的 channel 会 panic。
defer 和 return 执行的先后顺序?
在 Go 语言中,defer 和 return 的执行顺序如下:
- return 语句不是一条单独的语句,实际上,它是由赋值和返回两部分组成的。赋值步骤会先执行,这一步会计算 return 语句中的表达式,然后赋值给返回值。
- defer 语句在函数返回前(即return语句后的返回动作执行前)执行。如果有多个 defer 语句,那么它们会以 LIFO(后进先出,即栈)的顺序执行。
- 返回动作,这是 return 语句的第二部分,这一步会携带返回值返回到调用函数。
所以,如果你在一个函数中写入了 defer 和 return,那么它们的执行顺序是:先执行 return 语句的赋值部分,然后执行 defer 语句,最后执行 return 语句的返回动作。
func foo() (result int) {
defer func() {
// 修改返回值
result++
}()
return 0 // return 语句的赋值部分先执行,然后执行 defer,最后执行 return 的返回动作
}在这个例子中,函数 foo 会返回 1,而不是 0。因为 return 0 是先赋值 result 为 0,然后 defer 函数把 result 增加了 1,最后返回 result,所以返回值是 1。
Golang 如何实现多态的效果
package main
import (
"fmt"
)
// 定义一个接口
type Shape interface {
Area() float64
}
// 定义一个矩形结构体
type Rectangle struct {
Width float64
Height float64
}
// 实现 Shape 接口的 Area 方法
func (r Rectangle) Area() float64 {
return r.Width * r.Height
}
// 定义一个圆形结构体
type Circle struct {
Radius float64
}
// 实现 Shape 接口的 Area 方法
func (c Circle) Area() float64 {
return 3.14 * c.Radius * c.Radius
}
// 打印形状的面积
func printArea(s Shape) {
fmt.Printf("Area: %f\n", s.Area())
}
func main() {
// 创建一个矩形
rectangle := Rectangle{Width: 10, Height: 5}
// 创建一个圆形
circle := Circle{Radius: 7}
// 使用多态调用 printArea 函数
printArea(rectangle) // 输出: Area: 50.000000
printArea(circle) // 输出: Area: 153.860000
}P 和 M 数量是可以无限扩增的吗?
- G 的数量:理论上没有数量上限限制的。查看当前G的数量可以使用
runtime.NumGoroutine()。 - P 的数量:由启动时环境变量
$GOMAXPROCS或者是由runtime.GOMAXPROCS()决定。这意味着在程序执行的任意时刻都只有$GOMAXPROCS个 goroutine 在同时运行。 - M 的数量:go 程序启动时,会设置 M 的最大数量,默认 10000。但是内核很难支持这么多的线程数,所以这个限制可以忽略。
runtime/debug中的 SetMaxThreads 函数可以设置 M 的最大数量。一个 M 阻塞了,会创建新的 M。M 与 P 的数量没有绝对关系,一个 M 阻塞,P 就会去创建或者切换另一个 M,所以,即使 P 的默认数量是 1,也有可能会创建很多个 M 出来。
G 在 GMP模型中流动过程
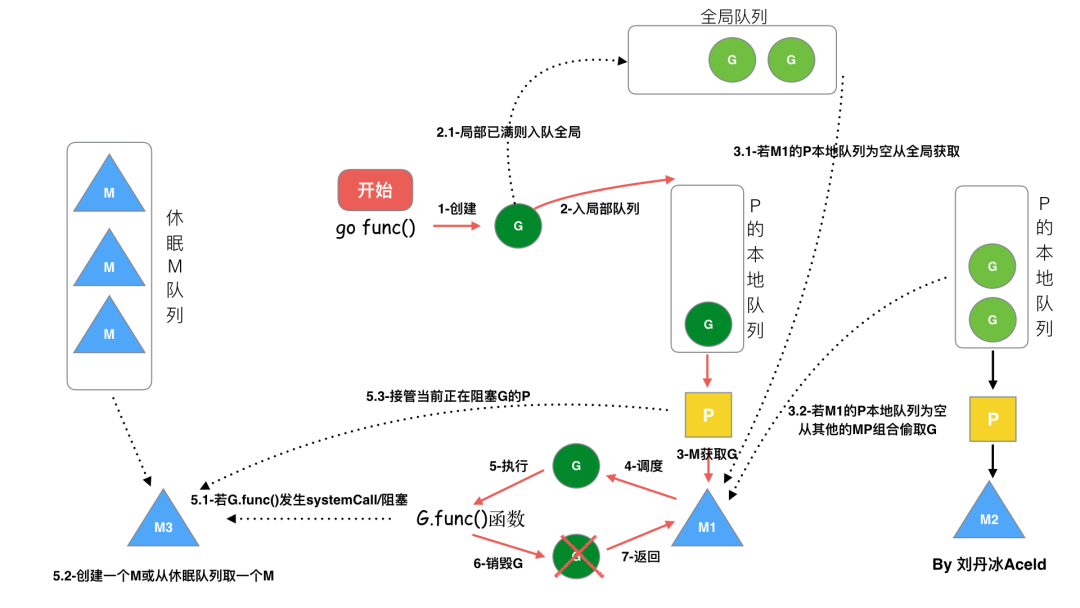
- 调用
go func()创建一个goroutine;
- 调用
- 新创建的 G 优先保存在 P 的本地队列中,如果 P 的本地队列已经满了就会保存在全局的队列中;
- M 需要在 P 的本地队列弹出一个可执行的 G,如果 P 的本地队列为空,则先会去全局队列中获取 G,如果全局队列也为空则去其他 P 中偷取 G 放到自己的 P 中;
- G 将相关参数传输给 M,为 M 执行 G 做准备;
- 当 M 执行某一个 G 时候如果发生了系统调用产生导致 M 会阻塞,如果当前 P 队列中有一些 G,runtime 会将线程 M 和 P 分离,然后再获取空闲的线程或创建一个新的内核级的线程来服务于这个 P,阻塞调用完成后 G 被销毁将值返回;
- 销毁 G,将执行结果返回;
- 当M系统调用结束时候,这个 M 会尝试获取一个空闲的 P 执行,如果获取不到 P,那么这个线程M变成休眠状态, 加入到空闲线程中。
GM 与 GMP 区别
在 12 年的 go1.1 版本之前用的都是 GM 模型,但是由于 GM 模型性能不好,饱受用户诟病。之后官方对调度器进行了改进,变成了我们现在用的GMP模型。
优化点有三个,一是每个 P 有自己的本地队列,而不是所有的 G 操作都要经过全局的 G 队列,这样锁的竞争会少的多的多。而 GM 模型的性能开销大头就是锁竞争。
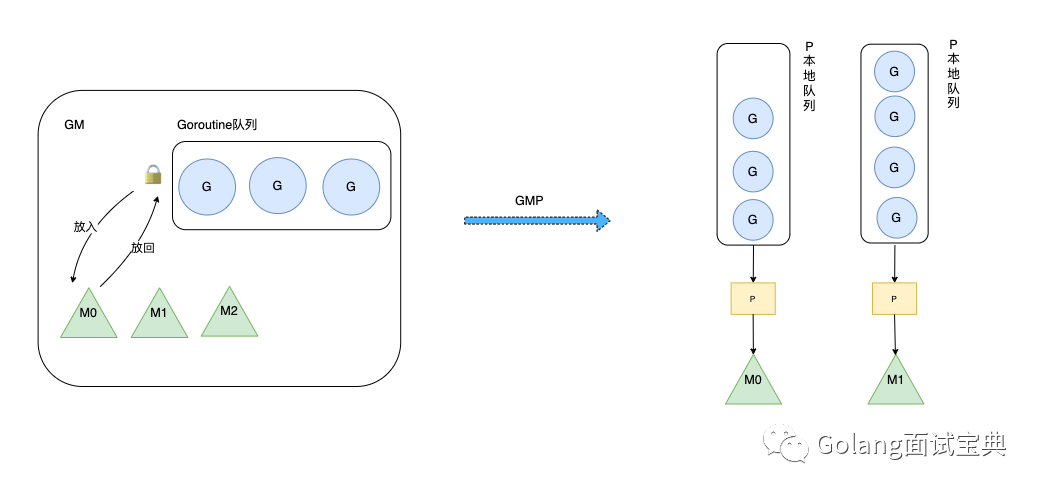
二是 P 的本地队列平衡上,在 GMP 模型中也实现了 Work Stealing 算法,如果 P 的本地队列为空,则会从全局队列或其他 P 的本地队列中窃取可运行的 G 来运行(通常是偷一半),减少空转,提高了资源利用率。

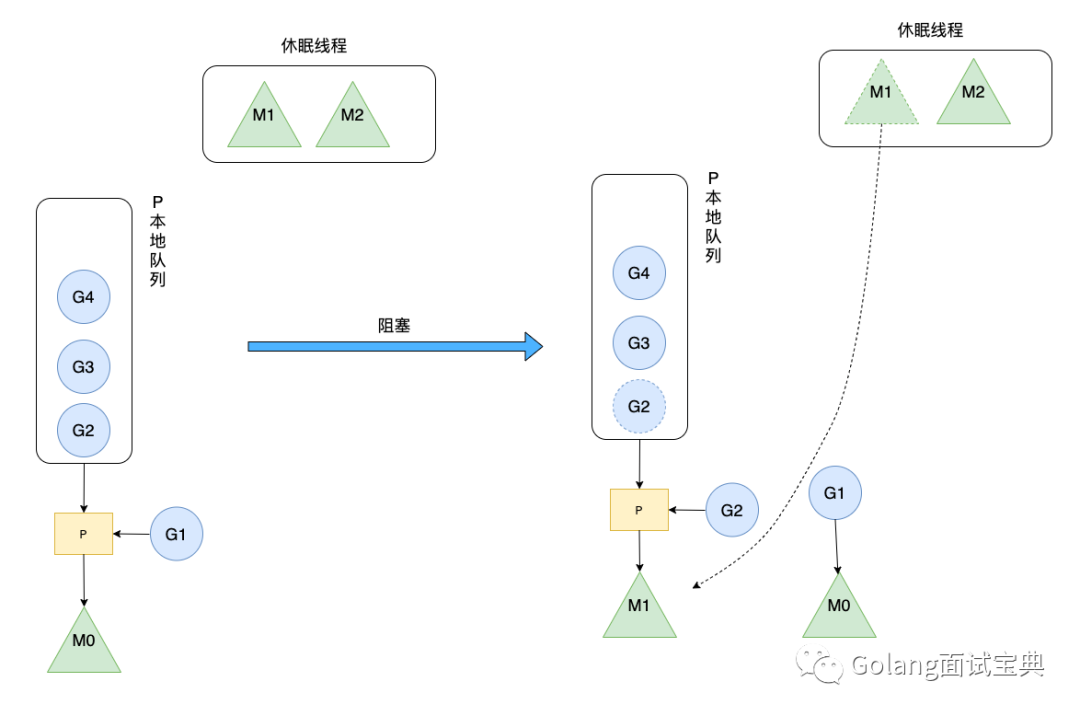
三是 hand off 机制,当 M0 线程因为 G1 进行系统调用阻塞时,线程释放绑定的 P,把 P 转移给其他空闲的线程 M1 执行,同样也是提高了资源利用率。
参考资料: