为什么模型训练通常需要分布式进行,而分布式模型预测并不常见?
计算模式不同:
- 训练需要各个 worker 保持通信,从而协调统一地更新模型参数。
- 预测中的模型参数是固定的,各个 worker 分别使用只读副本,无需相互通信协调。
AI 集群规模越大越好?大集群拥有大算力?
集群训练引入通信开销,集群的算力并不是线性增长,增加 GPU 计算节点,并不能线性地提升算力收益。 要想通过 AI 集群提升更多算力,需要优化服务器间通信、拓扑、模型并行、分布式框架等软硬件协同。
对于网络而言,高速、低延迟的网络可以缩短节点间同步梯度的时间,加快训练过程;对于计算而言,降低不必要的计算资源消耗,使计算节点能够专注于训练任务。
什么是 Tensor Core?
Tensor Core 是英伟达推出专门用于深度学习和 AI 计算的硬件单元。Tensor Core 的设计旨在加速矩阵乘法运算,这在深度学习中是非常常见的计算操作。Tensor Core 主要有以下特点和优势:
- 并行计算能力:Tensor Core 能够同时处理多个矩阵乘法运算,从而大幅提高计算效率。
- 混合精度计算:Tensor Core 支持混合精度计算,即同时使用浮点 16 位(half-precision)和浮点 32 位(single-precision)数据类型进行计算,以在保证计算精度的同时提高计算速度。
- 高性能计算:Tensor Core 具有非常高的计算性能,能够快速处理大规模的神经网络模型和数据集。
- 节能优势:由于其高效的并行计算和混合精度计算能力,Tensor Core 在相同计算任务下通常能够比传统的计算单元更节能。
什么是卷积?
卷积是神经网络里面的核心计算之一,它是一种特殊的线性运算。
什么是卷积神经网络?
卷积神经网络(Convolution Neural Networks, CNN)是针对图像领域任务提出的神经网络,其受猫的视觉系统启发,堆叠使用卷积层和池化层提取特征。它在 CV 领域方面的突破性进展引领了深度学习的热潮。
有哪些常见的神经网络模型?
什么是混合精度训练?它的优点是什么?
混合精度训练实际上是一种优化技术,它通过在模型训练过程中灵活地使用不同的数值精度来达到加速训练和减少内存消耗的目的。具体来说,混合精度训练涉及到两个关键操作:
- 计算的精度分配:在模型的前向传播和反向传播过程中,使用较低的精度(如 FP16)进行计算,以加快计算速度和降低内存使用量。由于 FP16 格式所需的内存和带宽均低于 FP32,这可以显著提高数据处理的效率。
- 参数更新的精度保持:尽管计算使用了较低的精度,但在更新模型参数时,仍然使用较高的精度(如 FP32)来保持训练过程的稳定性和模型的最终性能。这是因为直接使用 FP16 进行参数更新可能会导致训练不稳定,甚至模型无法收敛,由于 FP16 的表示范围和精度有限,容易出现梯度消失或溢出的问题。
而在混合精度的实现上,其通常需要特定的硬件支持和软件优化。例如,英伟达的 Tensor Core 就是专门设计来加速 FP16 计算的,同时保持 FP32 的累加精度,从而使得混合精度训练成为可能。在软件层面,AI 框架如 PyTorch 和 MindSpore 等也提供了混合精度训练的支持,通过自动化的工具简化了实现过程。
PyTorch
DataParallel 与 DistributedDataParallel 的区别?
- DataParallel 是单进程多线程的,限制在单台机器上运行;而 DistributedDataParallel 是多进程的,支持单机和多机训练。
- 即使是在单台机器上,DistributedDataParallel 的性能也要比 DataParallel 更好。
- 当模型太大无法在单个 GPU 上运行时,需要使用模型并行。DistributedDataParallel 支持与模型并行结合,而 DataParallel 目前不支持。
参考资料:Comparison between DataParallel and DistributedDataParallel
vLLM
CUDA 已经使用虚拟地址空间管理显存了,为什么还需要 PagedAttention 来解决显存碎片问题呢?
早期的 CUDA API 中的 cudaMalloc 不支持按需分页,它会同时为虚拟内存和物理内存分配空间,无法将虚拟地址和物理地址的分配解耦。这导致在 LLM 推理中动态扩展 KV cache 时,无法有效利用分散的显存片段,从而造成显存浪费和碎片化问题。
因此,PagedAttention 在用户空间实现了按需动态分配内存的能力,将 KV cache 分割成固定大小的 block,仅在需要时分配物理内存。但 PagedAttention 也带来了新的问题:由于 PagedAttention 动态分配的 block 在虚拟内存中的地址通常不连续,因此需要修改 Attention 算子的实现,以支持在非连续内存块上进行计算,从而增加了计算的复杂度。(PagedAttention 的分页机制对应用程序并不透明,应用程序必须显式处理这些非连续的内存块;而传统操作系统的分页机制则对应用程序是透明的,应用程序认为自己始终在访问连续的内存。)
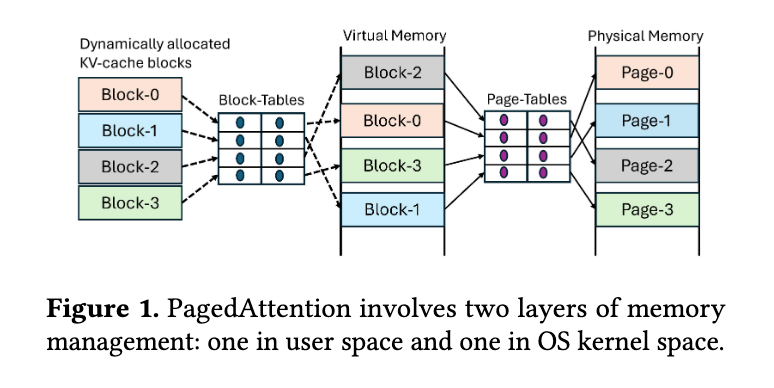
虽然 CUDA VMM API 在 CUDA 10.2(2019 年 11 月)中就已引入,提供了细粒度控制虚拟和物理内存的能力,将显存的虚拟地址和物理地址的分配解耦,允许编程人员分别处理它们。但直到 2023 年左右,大家才开始使用这些底层 API。当时 PagedAttention 可能尚未考虑到这一机制,因此选择在用户空间自行实现按需动态分配内存的功能。
而新的 vAttention 正是利用了 CUDA VMM API 这一底层接口,通过 cuMemAddressReserve 预先分配一段连续的虚拟地址空间,再结合 cuMemCreate 和 cuMemMap 按需映射物理内存,实现了在保持 KV cache 虚拟地址连续性的同时,减少物理内存碎片化的关键特性,提供了更优雅的解决方案。
参考资料:
- 知乎问题:CUDA已经使用虚拟地址空间管理显存了,那为啥还需要PagedAttention解决显存碎片问题呢?
- [Feature]: Implement vAttention: Virtual Memory Management for KV Cache on NVIDIA GPUs
- [Hardware][Nvidia][Core][Feature] new feature add: vmm(virtual memory manage) kv cache for nvidia gpu
- vAttention: Dynamic Memory Management for Serving LLMs without PagedAttention