容器 CPU 和内存限制在 cgroup 中的实现
在 Pod Spec 里的设置的 CPU 和内存限制,实际上是通过 cgroup 实现的。cgroup 是 Linux 内核提供的一种机制,用于限制、记录和隔离一组进程的资源使用。cgroup 通过文件系统的方式将一组进程组织在一起,并为这组进程分配资源。
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
env:
resources:
requests:
memory: "64Mi"
cpu: "1"
limits:
memory: "128Mi"
cpu: "2"CPU
- CPU requests 经过转换之后会写入 cpu.share,表示这个 Cgroup 最少需要使用的 CPU。cpu.shares 这个值决定了 CPU Cgroup 子系统下控制组可用 CPU 的相对比例,不过只有当系统上 CPU 完全被占满的时候,这个比例才会在各个控制组间起作用。
- CPU limits 经过转换之后会写入 cpu.cfs_quota_us,表示这个 Cgroup 最多可以使用的 CPU;cpu.cfs_quota_us(一个调度周期内这个控制组被允许运行的时间) 和 cpu.cfs_period_us(CFS 算法的调度周期,一般是 100000)这两个值决定了每个控制组中所有进程的可使用 CPU 资源的最大值。例如,如果 cpu.cfs_quota_us 设置为 50000,cpu.cfs_period_us 设置为 100000,那么这个控制组中的所有进程在一个调度周期内最多只能运行 50% 的 CPU 时间。
内存
- cgroup 不能直接限制内存的最少使用量。
- Memory limits 经过转换之后会写入 memory.limit_in_bytes, 表示这个 cgroup 最多可以使用的内存。
调度只看 requests: 如果一个 Node 的 Allocatable 剩余资源大于 Pod 的 requests ,就允许这个 pod 调度到这台 node 上。limits 是限额用的,确保资源不会用超,在调度时用不到。
systemd 和 cgroupfs 驱动是什么?
kubelet 和底层容器运行时都需要对接 cgroup 来设置 Pod 和容器的 CPU、内存等资源的请求和限制。若要对接 cgroup,kubelet 和容器运行时(如 containerd, CRI-O)需要使用同一个 cgroup 驱动。
kubelet 和容器运行时需使用相同的 cgroup 驱动并且采用相同的配置。同时存在两个 cgroup 管理器将造成系统中针对可用的资源和使用中的资源出现两个视图。某些情况下, 将 kubelet 和容器运行时配置为使用 cgroupfs、但为剩余的进程使用 systemd 的那些节点将在资源压力增大时变得不稳定。
- 当使用 cgroupfs 驱动时, kubelet 和容器运行时将直接对接 cgroup 文件系统来配置 cgroup。
- 使用 systemd cgroup 驱动时,所有 cgroup-writing 操作都必须通过 systemd 的接口,不能手动修改 cgroup 文件。当 systemd 是初始化系统时, 不推荐使用 cgroupfs 驱动,因为 systemd 期望系统上只有一个 cgroup 管理器。 此外,如果你使用 cgroup v2,则应用 systemd cgroup 驱动取代 cgroupfs。 从 v1.22 开始,在使用 kubeadm 创建集群时,如果用户没有在 KubeletConfiguration 下设置 cgroupDriver 字段,kubeadm 默认使用 systemd。
要将 systemd 设置为 cgroup 驱动,需编辑 KubeletConfiguration 的 cgroupDriver 选项,并将其设置为 systemd。例如:
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
...
cgroupDriver: systemd在 containerd 中,可以通过配置文件 /etc/containerd/config.toml 来设置使用 systemd cgroup 驱动。例如:
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]
...
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true参考资料
kubelet 的 cgroup 层级有哪些?
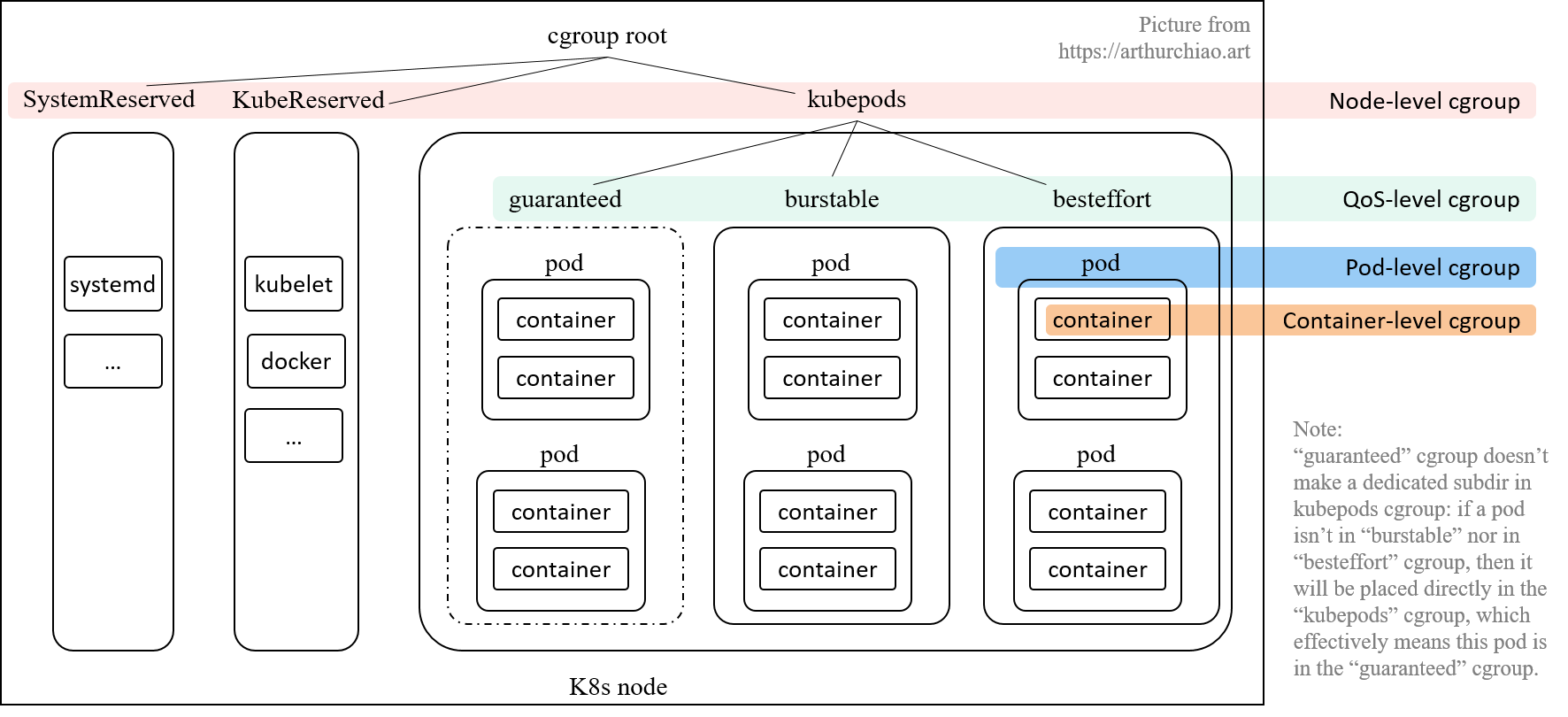
- Node 级别:针对 SystemReserved、KubeReserved 和 kubepods 分别创建的三个 cgroup;cgroup v1 是按 resource controller 类型来组织目录的, 因此,/kubepods 会按 resource controller 对应到 /sys/fs/cgroup/{resource controller}/kubepods/,例如:
/sys/fs/cgroup/cpu/kubepods//sys/fs/cgroup/memory/kubepods/
- QoS 级别:在 kubepods cgroup 里面,又针对三种 pod QoS 分别创建一个 sub-cgroup:
- Burstable: 默认
/sys/fs/cgroup/{controller}/kubepods/burstable/; - BestEffort: 默认
/sys/fs/cgroup/{controller}/kubepods/besteffort/; - Guaranteed:这个比较特殊,直接就是
/sys/fs/cgroup/{controller}/kubepods/,没有单独的子目录。这是因为这种类型的 pod 都设置了 limits, 就无需再引入一层 wrapper 来防止这种类型的 pods 的资源使用总量超出限额。
- Burstable: 默认
- Pod 级别:每个 pod 创建一个 cgroup,用来限制这个 pod 使用的总资源量;
- Container 级别:在 pod cgroup 内部,限制单个 container 的资源使用量。
参考资料:
Pod 中有多个容器时,Pod 的 requests/limits 等于各个容器 requests/limits 之和吗?
并不是。这是因为:
- 某些资源是这个 Pod 的所有 container 共享的;
- 每个 pod 也有自己的一些开销,例如 sandbox container;
- Pod 级别还有一些内存等额外开销;
因此,为了防止一个 pod 的多个容器使用资源超标,k8s 引入了 pod-level cgroup,每个 pod 都有自己的 cgroup。
参考资料:
Kubernetes Pod 的 Qos 类型有哪几种?
- Guaranteed: requests == limits, requests != 0, 即 正常需求 == 最大需求,换言之 spec 要求的资源量必须得到保证,少一点都不行;
- Burstable: requests < limits, requests != 0, 即 正常需求 < 最大需求,资源使用量可以有一定弹性空间;
- BestEffort: request == limits == 0, 创建 pod 时不指定 requests/limits 就等同于设置为 0,kubelet 对这种 pod 将尽力而为;
container_memory_usage_bytes 和 container_memory_working_set_bytes 指标的区别是什么?
- container_memory_usage_bytes:表示当前容器使用的总内存量,包括所有类型的内存(例如,活跃内存、缓存和文件系统缓存等)。
- container_memory_working_set_bytes:通常指的是实际在使用中的内存量,不包含可以被系统回收的页面缓存。OOM Killer 会根据这个指标来决定是否终止容器以释放资源。
参考资料:
节点上怎么实现 CPU 和 内存监控的,分别监控了哪些具体的指标?
CPU 使用率:
100 - (avg by (instance) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)内存使用率:
(node_memory_MemTotal - node_memory_MemFree - node_memory_Buffers - node_memory_Cached) / node_memory_MemTotal * 100OOM 了以后,Pod 一定会被杀死吗?
不一定。当 cgroup 超过其极限时,首先尝试从 cgroup 中回收内存,以便为 cgroup 所管理的新页面腾出空间。如果回收不成功,将调用 OOM 程序来选择并终止 cgroup 内最庞大的任务。
另外只有当 Container 中 pid 为 1 的程序被 OOM-killer 杀死时,Container 才会被标记为 OOM killed,有些应用程序可以容忍非 init 进程的 OOM kills,因此 Kubernetes 选择不跟踪非 init 进程 OOM kill 事件,这是预期的方式。
参考资料:
- Kubernetes学习(kubernetes中的OOM-killer和应用程序运行时含义)
- Out-of-memory (OOM) in Kubernetes – Part 2: The OOM killer and application runtime implications
- Memory Resource Controller: 2.5 Reclaim
为什么程序收不到 SIGTERM 信号?
我们的业务代码通常会捕捉 SIGTERM 信号,然后执行停止逻辑以实现优雅终止。例如以下代码:
package main
import (
"fmt"
"os"
"os/signal"
"syscall"
)
func main() {
sigs := make(chan os.Signal, 1)
done := make(chan bool, 1)
// registers the channel
signal.Notify(sigs, syscall.SIGTERM)
go func() {
sig := <-sigs
fmt.Println("Caught SIGTERM, shutting down")
// Finish any outstanding requests, then...
done <- true
}()
fmt.Println("Starting application")
// Main logic goes here
<-done
fmt.Println("exiting")
}然而业务在 Kubernetes 环境中实际运行时,有时候可能会发现在滚动更新时,我们业务的优雅终止逻辑并没有被执行,现象是在等了较长时间后,业务进程直接被 SIGKILL 强制杀死了。
通常都是因为容器启动入口使用了 shell,比如使用了类似 /bin/sh -c my-app 这样的启动入口。 或者使用 /entrypoint.sh 这样的脚本文件作为入口,在脚本中再启动业务进程。
这就可能就会导致容器内的业务进程收不到 SIGTERM 信号,原因是:
- 容器主进程是 shell,业务进程是在 shell 中启动的,成为了 shell 进程的子进程。
- shell 进程默认不会处理 SIGTERM 信号,自己不会退出,也不会将信号传递给子进程,导致业务进程不会触发停止逻辑。
如何解决?
- 如果可以的话,尽量不使用 shell 启动业务进程。
- 如果一定要通过 shell 启动,比如在启动前需要用 shell 进程一些判断和处理,或者需要启动多个进程,那么就需要在 shell 中传递下 SIGTERM 信号了,有 3 种方式可以实现:
1.使用 exec 命令,替换 shell 进程,这样 shell 进程就变成了主进程,直接接收到 SIGTERM 信号。
#! /bin/bash
...
exec /bin/yourapp # 脚本中执行二进制2.使用 trap 命令,捕捉 SIGTERM 信号,然后转发给子进程。
#! /bin/bash
/bin/app1 & pid1="$!" # 启动第一个业务进程并记录 pid
echo "app1 started with pid $pid1"
/bin/app2 & pid2="$!" # 启动第二个业务进程并记录 pid
echo "app2 started with pid $pid2"
handle_sigterm() {
echo "[INFO] Received SIGTERM"
kill -SIGTERM $pid1 $pid2 # 传递 SIGTERM 给业务进程
wait $pid1 $pid2 # 等待所有业务进程完全终止
}
trap handle_sigterm SIGTERM # 捕获 SIGTERM 信号并回调 handle_sigterm 函数
wait # 等待回调执行完,主进程再退出3.使用 tini 这样的工具,tini 是一个轻量级的 init 系统,专门用来解决容器环境下的信号处理问题。
FROM ubuntu:22.04
ENV TINI_VERSION v0.19.0
ADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /tini
COPY entrypoint.sh /entrypoint.sh
RUN chmod +x /tini /entrypoint.sh
ENTRYPOINT ["/tini", "--"]
CMD [ "/start.sh" ]参考资料:
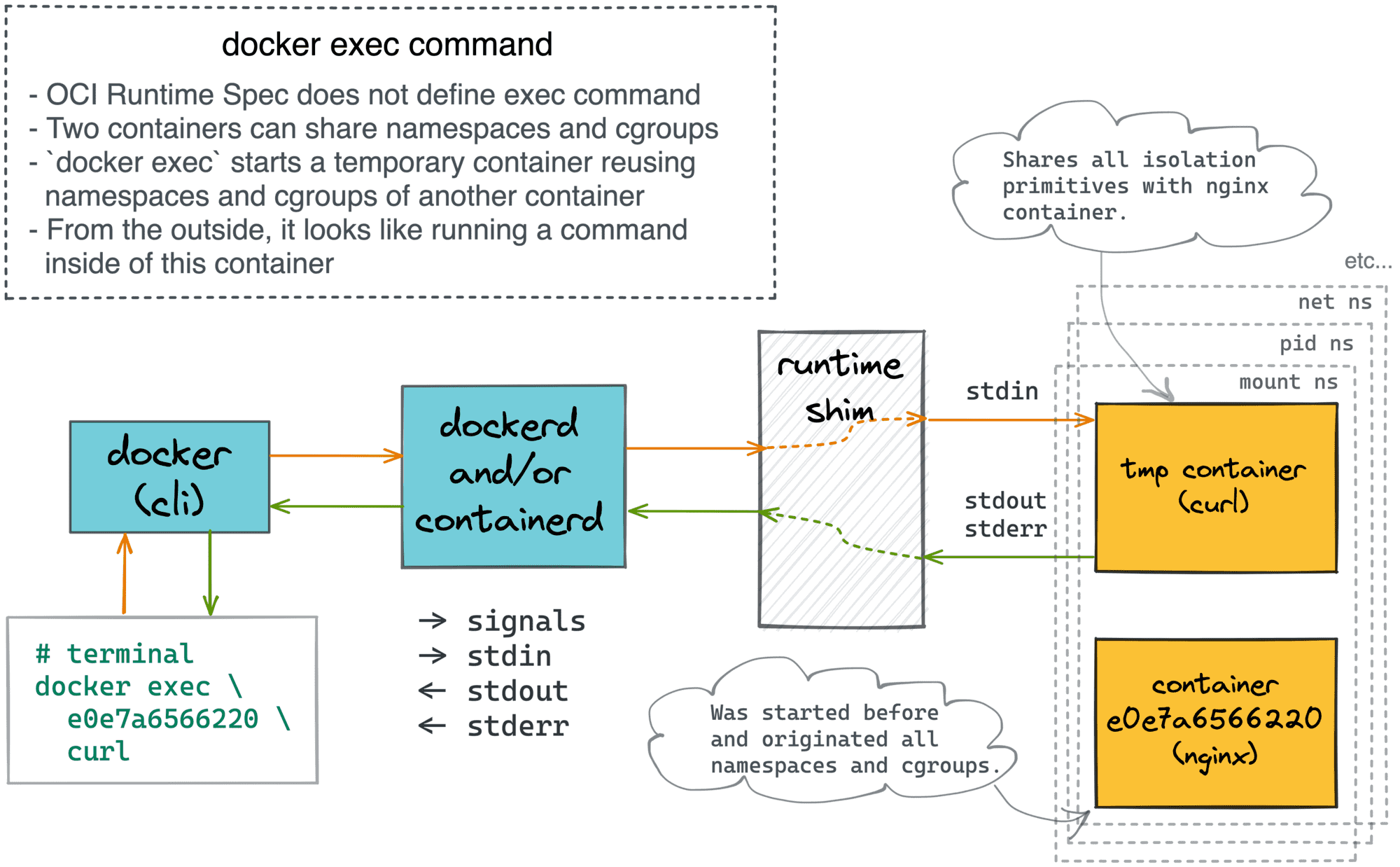
docker attach 和 docker exec 命令有什么区别?
docker attach 命令通过 shim 进程连接到容器的 stdio 流,允许用户访问容器的日志并与之交互。在 attach 的 stdin 执行 exit 命令时,容器会被停止。

docker exec 创建一个新的辅助容器,共享目标容器的 net, pid, mount 等命名空间、相同的 cgroups 层次结构等。从外部来看,感觉就像在现有容器内运行命令。在 exec 的 stdin 执行 exit 命令时,容器不会被停止,因为 exit 的是新创建的辅助容器。
参考资料:
如何正确地获取容器中的 CPU 利用率?
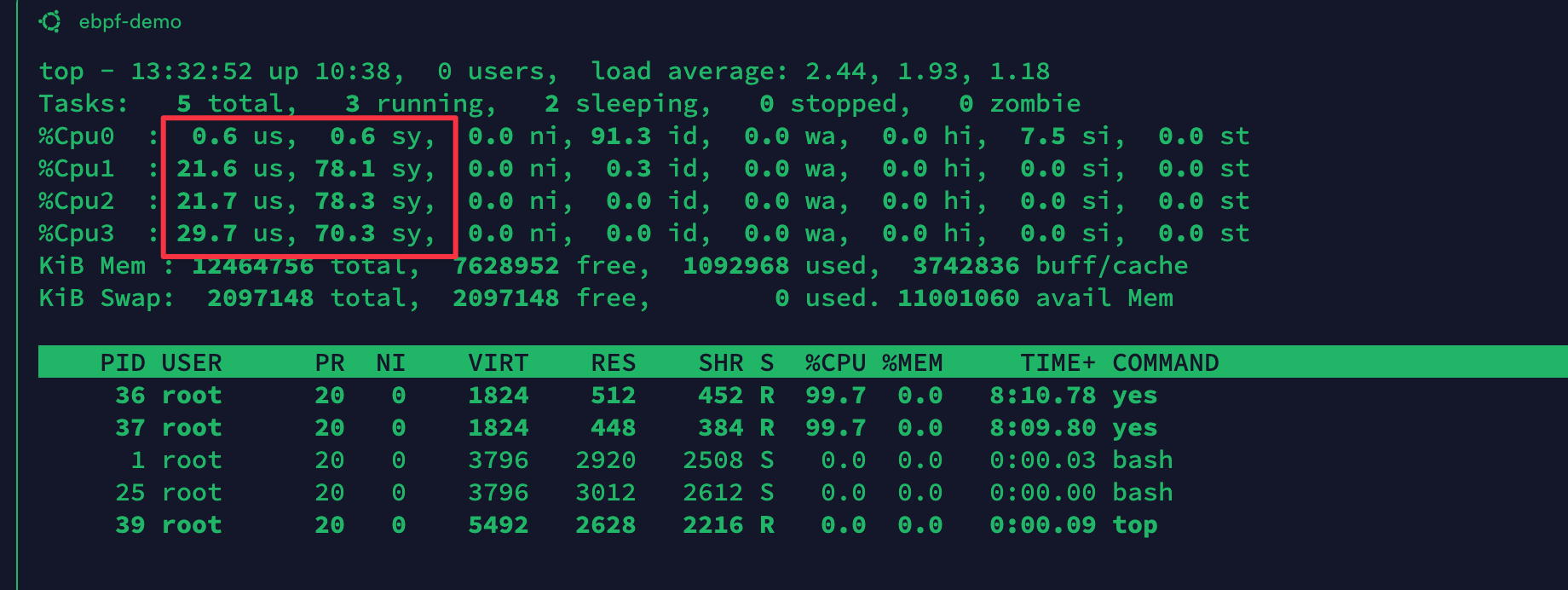
在容器中如果我们使用 top 命令查看容器的 CPU 利用率,会发现其实看到是宿主机的 CPU 利用率。 这是因为在默认情况下,容器中的 /proc/stat 并没有单独挂载,而是使用的宿主机的。而 top 命令中对 CPU 核数的判断,以及对 CPU 利用率的显示都是根据 /proc/stat 文件的输出来计算的。
在容器中启动两个进程,这两个进程会尝试占满所有的 CPU 资源,从而使 CPU 使用率达到 200%。
yes > /dev/null &
yes > /dev/null &在容器中使用 top 命令可以看到 CPU 的使用率是 0.6% + 0.6% + 21.6% + 78.1% + 21.7% + 78.3% + 29.7% + 70.3% = 300.9%,而容器的 CPU使用率其实应该是 200% 左右。
要想正确地获取容器中的 CPU 利用率,有 3 种方法:
- 1.使用 docker stats 命令:
docker stats
CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
3a26224e8de9 funny_cohen 195.48% 2.223MiB / 512MiB 0.43% 3.36kB / 2.52kB 4.1kB / 4.1kB 5- 2.找到容器所属的 cgroup,根据
/sys/fs/cgroup/cpu.stat(cgroup v2) 中的usage_usec来计算 CPU 利用率。 在 cgroup v1 中,根据cpuacct.usage来计算 CPU 利用率。 kubelet 中集成的 cadvisor 就是采用上述方案来获取容器的 CPU 利用率。 以 cgroup v2 为例,CPU 的使用率为 (2501959062 - 2499873874) / 1000000 * 100 = 208%,其中 1000000(微妙) 是 sleep 1 秒的时间,乘 100 是为了得到百分比。
cat /sys/fs/cgroup/cpu.stat | grep usage_usec; sleep 1; cat /sys/fs/cgroup/cpu.stat | grep usage_usec
usage_usec 2499873874
usage_usec 2501959062- 3.使用 lxcfx 文件系统实现容器的资源视图隔离。 lxcfs 是通过文件挂载的方式,把 cgroup 中关于系统的相关信息读取出来,通过 docker 的 volume 挂载给容器内部的 proc 系统。 然后让 docker 内的应用读取 proc 中信息的时候以为就是读取的宿主机的真实的 proc。下面是 lxcfs 的工作原理架构图:
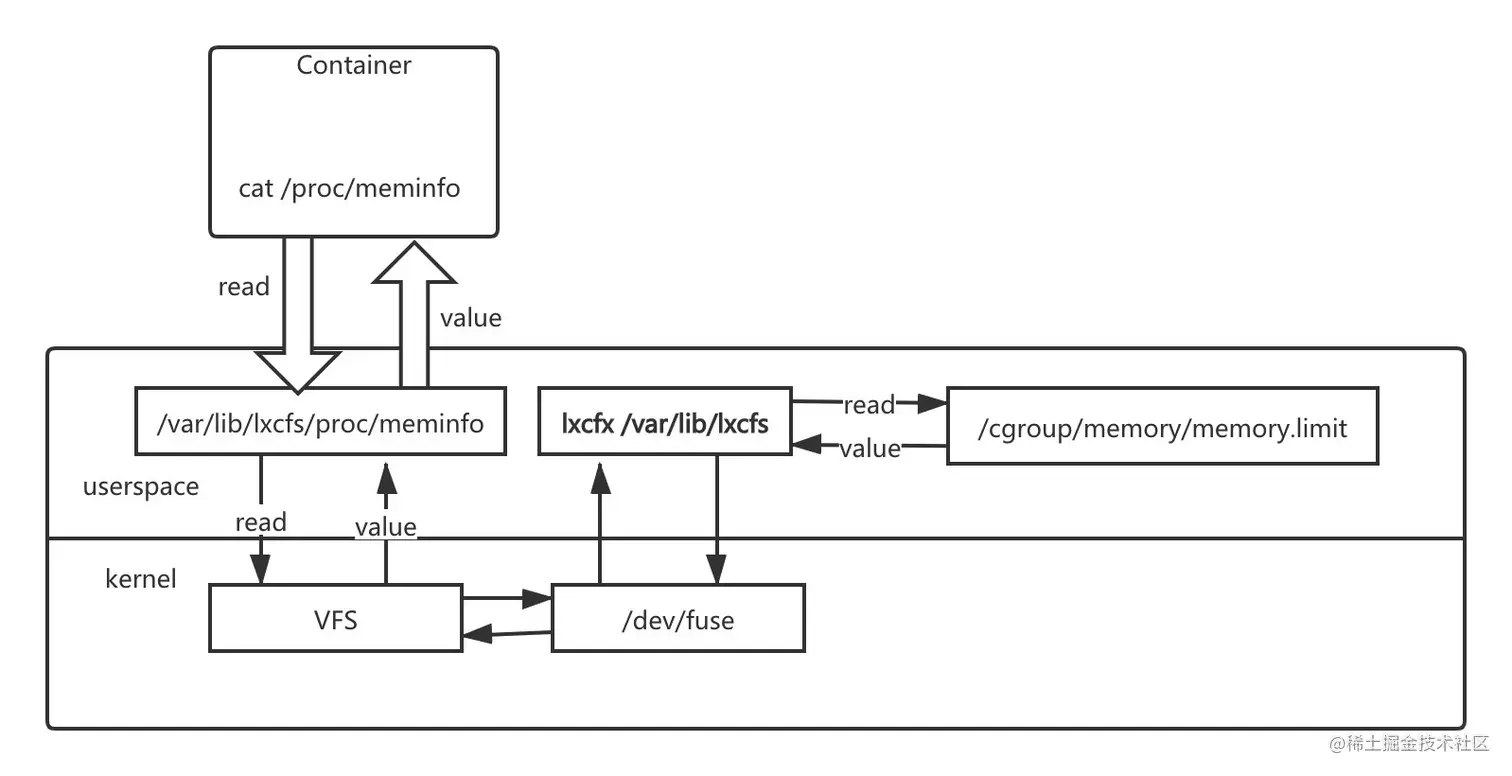
当我们把宿主机的 /var/lib/lxcfs/proc/memoinfo 文件挂载到 Docker 容器的 /proc/meminfo 位置后,容器中进程读取相应文件内容时,lxcfs 的 /dev/fuse 实现会从容器对应的 cgroup 中读取正确的内存限制。从而使得应用获得正确的资源约束。 CPU 的限制原理也是一样的。
lxcfx 的使用方式如下:
# 安装 lxcfs
apt-get install -y lxcfs
# 启动容器的时候将宿主机的 lxcfx 目录挂载到容器的 /proc 目录
# 在容器看到 CPU 个数是--cpuset 指定的 CPU 的个数
docker run -it --cpus 2 --cpuset-cpus "0,1" --memory 512m --rm \
-v /var/lib/lxcfs/proc/cpuinfo:/proc/cpuinfo:rw \
-v /var/lib/lxcfs/proc/diskstats:/proc/diskstats:rw \
-v /var/lib/lxcfs/proc/meminfo:/proc/meminfo:rw \
-v /var/lib/lxcfs/proc/stat:/proc/stat:rw \
-v /var/lib/lxcfs/proc/swaps:/proc/swaps:rw \
-v /var/lib/lxcfs/proc/uptime:/proc/uptime:rw \
ubuntu:18.04 /bin/bash现在在容器中运行 top 命令,就可以看到容器正确的 CPU 利用率了。
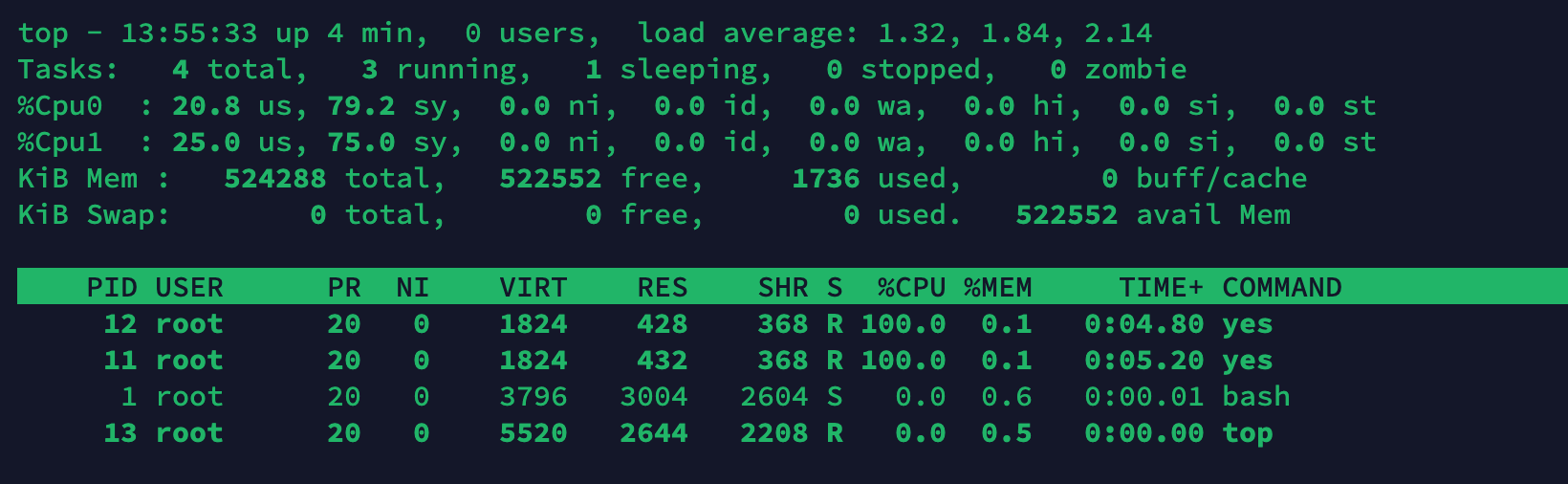
参考资料:
- 06 | 容器CPU(2):如何正确地拿到容器CPU的开销?
- 如何正确获取容器的CPU利用率?
- lxcfs 是什么? 怎样通过 lxcfs 在容器内显示容器的 CPU、内存状态
- lxcfs 是什么? lxcfs 实现对容器资源视图隔离的最佳实践
- Current Fulfiller of Metrics Endpoints & Future Proposal
为什么要做容器的资源视图隔离?
- 对于很多基于 JVM 的 JAVA 程序,应用启动时会根据系统的资源上限来分配 JVM 的堆和栈的大小。而在容器里面运行运行 JAVA 应用由于 JVM 获取的内存数据还是物理机的数据,而容器分配的资源配额又小于 JVM 启动时需要的资源大小,就会导致程序启动不成功。
- 对于需要获取 CPU 信息的程序,比如在开发 Golang 服务端需要获取 Golang 中
runtime.GOMAXPROCS(runtime.NumCPU())或者运维在设置服务启动进程数量的时候(比如 Nginx 配置中的worker_processes auto),都喜欢通过程序自动判断所在运行环境 CPU 的数量。但是在容器内的进程总会从/proc/cpuinfo中获取到 CPU 的核数,而容器里面的/proc文件系统还是物理机的,从而会影响到运行在容器里面服务的运行状态。